
Understand how Data2vec achieves general self-supervision on speech, vision, and text data

Moden data is complex, diverse, and unsupervised. Data can have different modalities, such as text, image, and audio.
In the last two decades, Artificial intelligence (AI) has demonstrated powerful predictive capabilities to handle any kind of data. However, each type of data requires different training and processing techniques.
Existing AI systems fail to provide a generic model capable of handling such diversified input simultaneously. The typical approach is to develop separate algorithms for every input source.
To fill the gap, researchers at Meta devised a general self-supervised learning solution called data2vec that works on speech, vision, and text data at once.
In this post, we’ll explore self-supervision and discuss the data2vec architecture. We’ll also compare the performance of data2vec with the existing state-of-the-art speech, language, and image models to understand how self-supervision can potentially develop truly intelligent AI systems in the future.
What Is Self-Supervised Learning?
Before YOLO, models like Region-based Convolutional Neural Networks (R-CNN) and Deformity Parts Models (DPP) dominated the object detection space. DPP takes up to 14 seconds to detect all objects in an image, processing around 0.07 frames per second (FPS). R-CNN takes around six seconds more than DPP processing around 0.05 FPS. Here’s how YOLO changes the game: it can process as many as 65 FPS on a V100 GPU, detecting all objects in an image with considerable accuracy in just 22 milliseconds.
Now, imagine a self-driving car using DPP or R-CNN. If the vehicle was traveling on the freeway at 60mph, and the algorithm took 20 seconds to detect objects on the road like people and other cars, it would have traveled 0.3 miles or over 500 meters. This would make collisions practically impossible to avoid. The typical distance from one car to another on the freeway is 3 meters (10 ft). Real-time object detection that can be used in self-driving cars must detect objects before the vehicle covers the 3 meters traveling at a relatively high speed. In the 60mph example, YOLO would identify the objects before the car moves a meter, making it a truly real-time object detection algorithm.
Why Do We Need a Generic Data Handling Strategy?
In AI, each data type is processed differently. Self-supervised language models are trained by hiding or masking a portion of input data and predicting this hidden information in the sentence. During training, the models build and train a vocabulary of discrete words, which aids in predicting the hidden words more accurately.
The training looks more complex for computer vision (CV) and speech models. Vision models predict the intensities of missing pixels in an image or video, while speech models learn sound waveforms to predict the missing audio or video sounds. However, no pre-existing vocabulary of speech units or visual tokens exists as they are continuous in nature.
Because each data source has varying informational units, i.e., characters or words for text, pixels for images, and sound waveforms for speech, a unified AI model cannot manage the diverse nature of training data.
Self-Supervised Data2vec Architecture Explained
Data2vec provides a unified training mechanism for text, speech, and vision data. Data2vec simplifies the learning process by training a transformer network, masking the input data, and allowing models to predict their representations of the input data.
Data2vec is trained using two networks: teacher and student. First, the teacher network computes numerical representations from input text passages, images, or speech audio. Next, the input is masked and delivered to the student network, where the numerical representations of the hidden input are predicted by updating weights. The two models have similar structures except that the teacher network has slightly outdated weights to assist self-supervised learning in the student network.
Let’s learn more about this training process in detail.
1. Transformer Architecture and Encoding Schemes
The transformer, developed initially for language problems, is now widely adopted for many self-supervised learning tasks across different data domains. The data2vec algorithm uses standard transformer architecture and encodes each input data according to its data type.
Images are encoded using the ViT-strategy as a sequence of pixel patches. Each patch spanning 16×16 pixels is linearly transformed and fed to the standard transformer.
Audio-based data is encoded using a multi-layer 1-D convolutional neural network that maps 16 kHz waveform to 50 Hz representations, similar to the encoding technique used in the wave2vec 2.0 self-supervised speech recognition model.
For the text data, word units are obtained by pre-processing, and the input is tokenized with byte-pair encoding.
2. Different Masking Strategies
Data2vec masks or hides some parts of the encoded input and feeds it to the transformer network.
The images are masked via block-wise masking strategy applied in BEiT, which hides multiple adjacent image patches. For audio data, data2vec uses the masking technique of the self-supervised wave2vec 2.0 speech model, while for language data, BERT token masking is adapted.
With a unified data handling strategy, the data2vec model can learn the underlying structure from any kind of unlabeled input data and predict information.
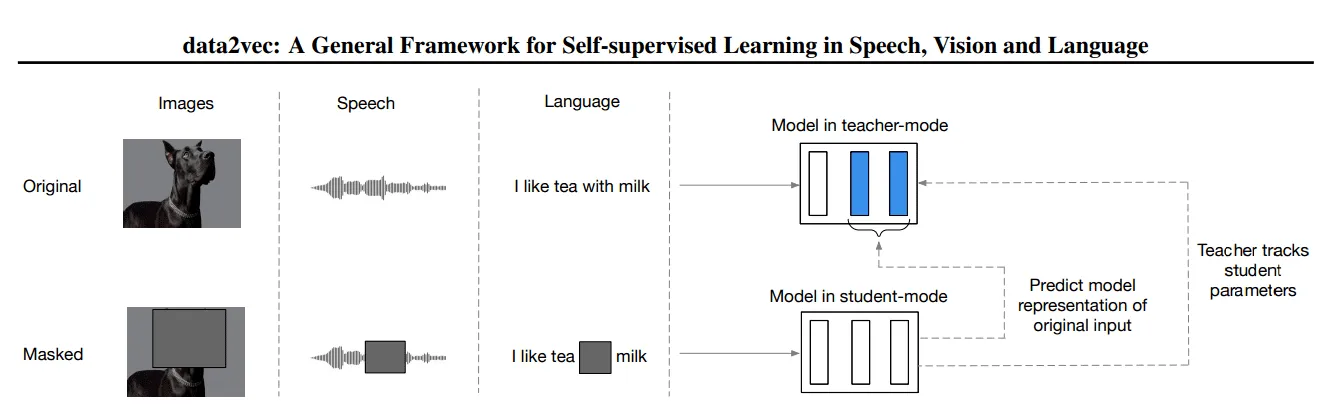
A general self-supervised Data2vec architecture to learn different input sources.
Comparison of Data2vec Performance With Benchmarked Techniques
Performance on Image Data
To evaluate data2vec for visual data, researchers at Meta pre-trained the model on the benchmark image data of ImageNet-1K. Data2vec was fine-tuned with the labeled data from the same benchmark for image classification task. Results show data2vec outperforms previous state-of-the-art image models like MoCov3, DINO, BeiT, etc.
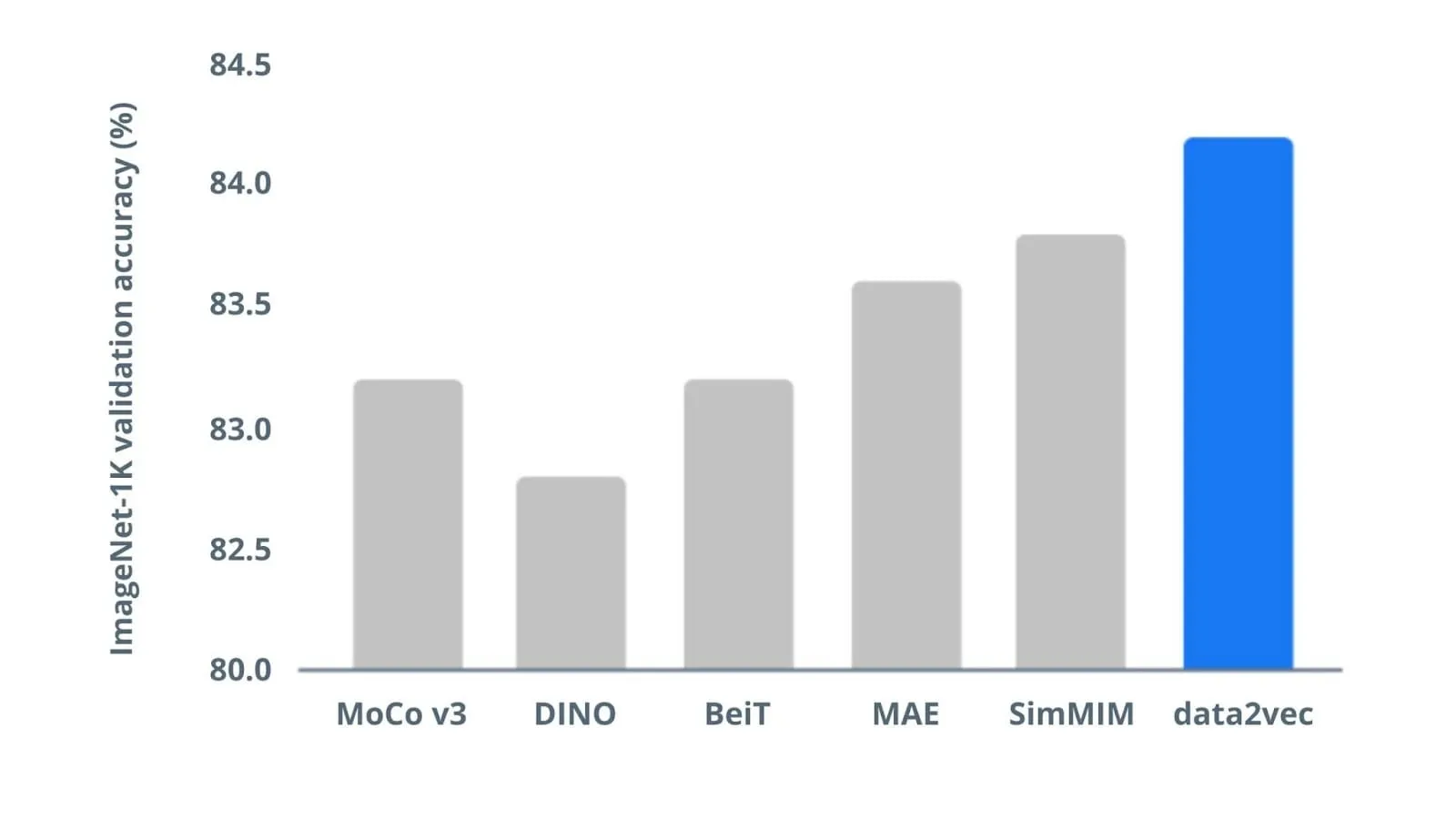
Data2vec vs. previous CV models. Image by Meta AI
Performance on Speech Audio
To assess speech processing capabilities, data2vec was pre-trained and fine-tuned on Librispeech audio data, which is composed of clean speech between 10 hours to 960 hours of duration (a standard benchmark in speech community). Data2vec was compared with previous state-of-the-art self-supervised speech recognition models like wav2vec 2.0 and HuBERT, and the results show improved performance of data2vec.
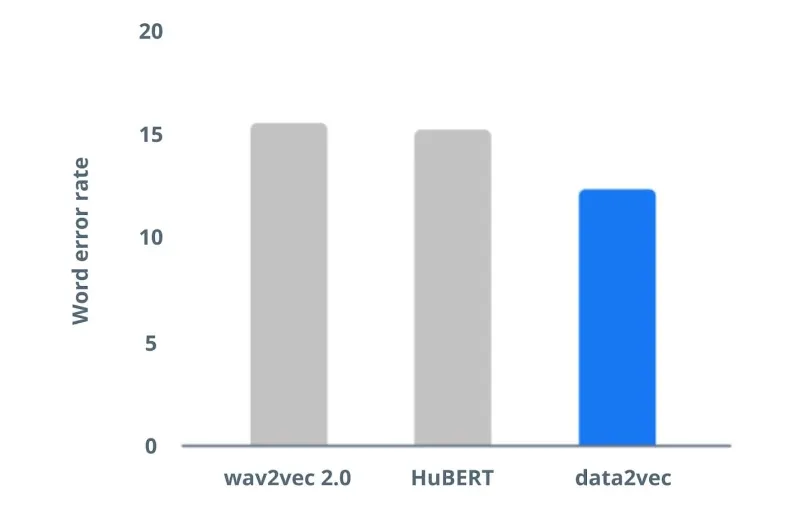
Low word error rate recorded for data2vec against Librispeech benchmark models with 10h labeled data. Image by Meta AI
Performance on Text Data
To compare the text-based performance of data2vec, a similar processing setup like BERT was replicated by pre-training on the Books Corpus and evaluating data2vec on General Language Understanding Evaluation (GLUE) benchmark. Comparison with RoBERTa baseline language model proves that data2vec slightly outperforms on text data as well.
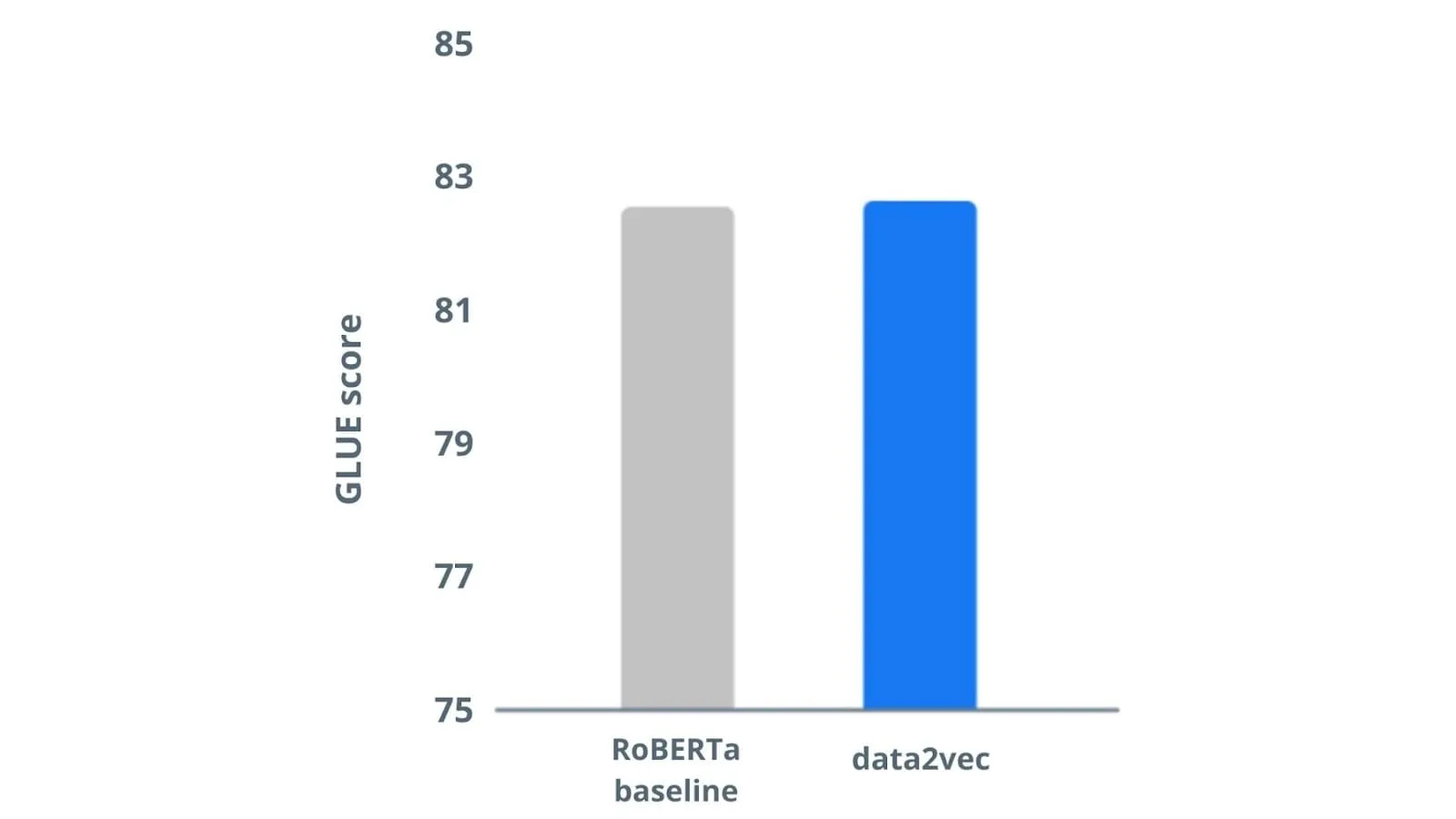
Data2vec scores are higher than the RoBERTa language model. Image by Meta AI
Data2vec has the potential to train multimodal data (text, audio, image) by using the self-supervision mechanism, enabling AI researchers to develop all-in-one models.
Limitations of Self-Supervised Data2vec
Data2vec is a significant step towards building more generalized AI models. But it has a few limitations.
Data2vec requires data-specific input encoding schemes. It also requires different masking schemes for each of the audio, image, and text data.
To build truly intelligent AI systems that learn by observing the real-world, future models should be able to process any kind of data using a unified encoding and masking approach.
Boost the Performance of Your AI Applications With High-Quality Data
Data is growing exponentially, so we need efficient AI solutions to manage it. With a general self-supervised learning approach, data2vec handles unlabeled and diverse image, text, and audio data effectively. However, self-supervised techniques require more research before applying them to real-world applications. Until then, AI systems must feed on high-quality labeled datasets.
DATUMO is a leading crowdsourcing platform that enables quick and accurate data collection and annotation for audio, video, image, and text data. Our highly-trained crowdsource workers can diligently tag, edit, classify, segment, and transcribe data as per your needs. Contact us today and start curating high-quality datasets to fuel your AI applications.


