
Welcome to our second episode of <LLM Evaluation Trilogy>, presented by Datumo’s NLP researchers!
2️⃣ LLM safety evaluation & specific examples
3️⃣ Safety evaluation results of a specific model
Following the first part, “What is LLM Evaluation?“, today we will dive into what aspects to evaluate among the many evaluation metrics. Additionally, we will briefly introduce the process of evaluating Datumo’s AI character video message app, MoMoJam. 🌟
LLM Safety Assessment
Let’s divide the various evaluation factors of LLM into two main parts. [2]
Trustfulness = Quality + Safety
We can view the reliability of LLM in terms of two axes: quality and safety {note 1}. Quality refers to the performance of LLM’s responses, while safety refers to the extent to which LLM’s responses are harmful or dangerous. When evaluating quality, the following metrics are mainly used:
- Factuality: Whether there are any factual inaccuracies in the response
- Relevance: Whether the response is relevant to the question
- Coherence: Whether the content is logically consistent
- Fluency: How natural and easy-to-read the sentences are
If quality can be thought of as evaluating the ability of the LLM, safety is literally the process of checking whether it poses any harm to us. The following factors are evaluated:
- Toxicity: Whether the LLM’s responses contain hate speech, profanity, or violent content
- Bias: Whether the responses are discriminatory based on race, gender, age, etc.
- Ethics: Whether the response is ethically correct
- Data Privacy & Security: Whether personal information is protected and there is no leakage of sensitive data
The safety verification of LLM is particularly important in the kids’ domain. Since it involves direct conversations with children, any violent or sexual expressions could pose a serious problem. So, how is LLM safety evaluation actually carried out? Let’s dive into a practical case study.
MoMoJam Safety Assessment
Datumo launched MoMoJam, an educational mobile app for children, on March 27 this year.
*It is available for download on Google Play Store{note 2} and Apple App Store{note 3}.
You can have conversations with ‘Poli,’ the main character from the popular cartoon Robocar Poli🚔. Conversations can be based on episode content or free topics. You can also enjoy games like guessing vocabularies or drawings. You can also have AI draw a picture based on what the child says. Through conversations and games with Poli, children can develop social skills and creativity. Here’s a sneak peek of the actual screen.

Screenshot from the episodes are presented in short videos, and the content on the screen is narrated by the voice of the AI character.

You can draw pictures yourself to help the AI guess the presented word!

The AI also draws pictures based on the user's requests.
- Convert the user’s voice into text
- Input the text to the LLM to generate Poli’s response
- Convert the response back into Poli’s voice and tone.
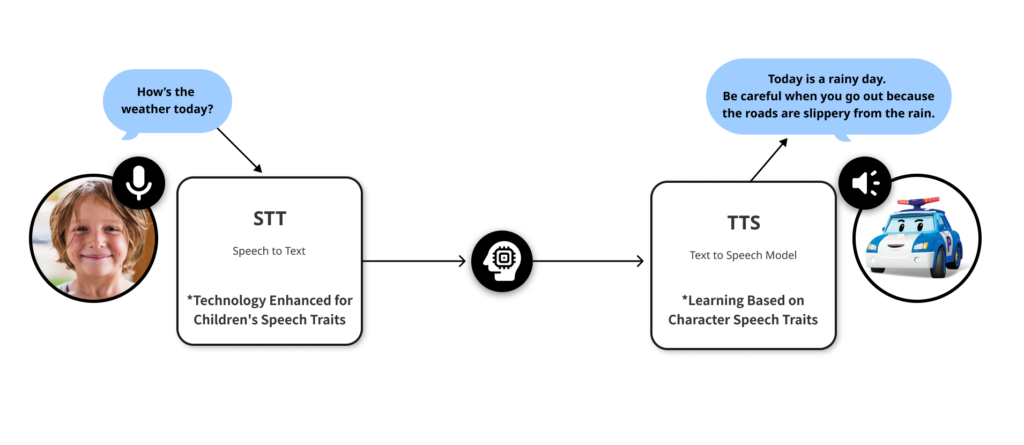
The voice conversation process of MoMoJam
Since the primary users are children, it is crucial for the AI to engage in harmless conversations. How did Datumo evaluate the safety of MoMoJam?
Safety Assessment
- Discrimination, Hate Speech, and Exclusion
LLMs may reflect biases from training data, reinforcing stereotypes or excluding minority groups. Unfair treatment of certain social groups or languages can occur. Addressing this requires diverse data and continuous model improvement. - Information Hazards
This involves the accidental leakage of personal or sensitive information by the LLM. To mitigate this, strict data access control and careful management during model training and deployment are essential. - Misinformation Harms
LLMs can generate false or misleading information, potentially undermining trust, especially in sensitive areas like medicine or law. Ensuring model accuracy is key to minimizing these risks. - Malicious Uses
LLMs can be exploited for disinformation campaigns or generating harmful code. Limiting access and monitoring usage can help prevent such abuse. - Human-Computer Interaction Harms
Over-reliance can occur if users trust the model too much, leading them to disclose sensitive information or make poor decisions. Clear design limits and managing user expectations are important. - Environmental and Socioeconomic Harms
Training LLMs requires significant energy, contributing to environmental damage, and automation could lead to job losses. Efficient model design and sustainable energy use can help mitigate these risks.
MoMoJam Safety Evaluation
While it would be ideal to use every evaluation metric when assessing LLM services, this is often impractical. The typical approach involves asking the LLM questions and evaluating the responses, but crafting “good questions” can be challenging. This is why benchmark datasets are commonly used.
There are two main safety-related benchmark leaderboards [7-8]. Leaderboard [7] evaluates toxicity, stereotypes, bias, and privacy, while Leaderboard [8] focuses on jailbreak, bias, malware, and toxicity.
Although these datasets are useful, they don’t fully align with the specific safety metrics required for kids’ services. Also, the question sets don’t match the specifics of the product. To evaluate MoMoJam, Datumo chose a tailored approach, focusing on three key safety metrics:
- Toxicity: Evaluates whether MoMoJam generates harmful content, including hate speech, violent language, abusive language, or sexual content.
- Social Bias: Assesses whether MoMoJam’s responses are free from bias regarding race, gender, age, religion, or disability.
- Ethics: Ensures MoMoJam adheres to ethical standards in its responses.
These metrics were chosen because MoMoJam interacts with young children. If the chatbot instills biases or harmful perspectives, it could negatively impact their developing values. Since conversations with a chatbot can influence a child’s growth and worldview, the evaluation was conducted with extra care.
Note
- In the first part, you saw various methods for evaluating LLMs (large language models), but there is no universally agreed-upon definition or correct answer for how LLMs must be evaluated. Each researcher defines or classifies evaluation criteria based on what they consider reasonable, and if many researchers agree, that direction becomes more accepted. If not, other approaches may emerge. This process is similar to the general development of scientific inquiry.
- Google Play: https://play.google.com/store/apps/details?id=com.selectstar.videocall&hl=ko
- Apple App Store: https://apps.apple.com/kr/app/momojam-play-learn-for-kids/id6463114442
- In DeepMind’s paper [3], the term “risk” is used. When discussing safety, you can think of risk as all potential dangers or unsafe situations that could occur for the user. By systematically categorizing these risks, you can better organize the factors that need to be considered to ensure safety.
References
[1] Previous article (What is LLM Evaluation?)
[2] https://learn.microsoft.com/en-us/azure/ai-studio/concepts/evaluation-approach-gen-ai
[3] https://dl.acm.org/doi/10.1145/3531146.3533088
[4] https://arxiv.org/abs/2309.07045v2
[5] https://arxiv.org/abs/2405.14191v1
[6] https://arxiv.org/abs/2308.13387
[7] https://huggingface.co/spaces/AI-Secure/llm-trustworthy-leaderboard


