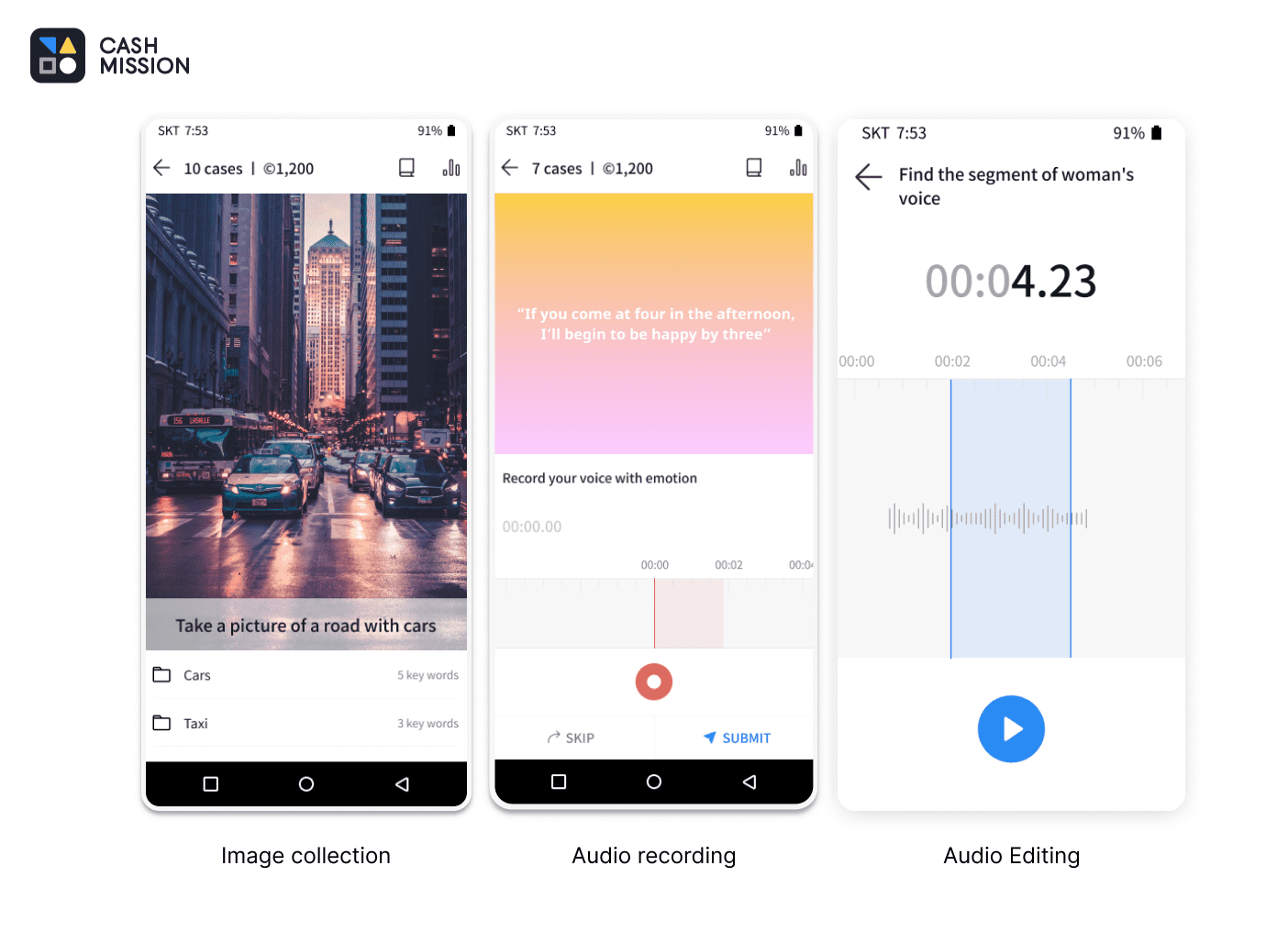
This Korean question and answer dataset for web documents MRC was created by LG CNS and Datumo. We created 80,000+ question and answer pairs based on Wikipedia which results in total of 100,000+ pairs of questions and answers, including those from KorQuAD 1.0.
About the dataset

Machine Reading Comprehension(MRC) is a natural language processing project which requires the AI model to comprehend the given text and the question, and point out the answer within the text. This is the core technology of automated question answering technology. The Korean standard dataset for MRC is called KorQuAD 1.0 and this dataset can be used not only for training AI models, but also as an objective standard to assess the performance of different models.
The preexisting Korean dataset performed question answering for short articles such as those from Wikipedia or the news. However, most texts we face in the real world, such as the texts from the web, product manuals, contracts, charts, lists, and so on, are constructed with various types of sentences. The sentences vary in structure, length, and complexity and most of the times MRC is required to perform within the whole text, rather than a single paragraph. As such, there was a gap between the actual tasks that needed MRC and academic research which eventually led to a problem of not being applicable, despite the algorithm’s academic performance.
In order to solve this problem, LG CNS created the KorQuAD 2.0 to enable machine reading comprehension for texts and documents with various types of sentences. Datumo collected training data of 80,000 question and answer pairs formed from approximately 50,000 Wikipedia texts. Additional to the 20,000 KorQuAD 1.0 dataset, Datumo and LG CNS created a total of 100,000 datasets.
Credit: https://korquad.github.io/dataset/KorQuAD_2.0/KorQuAD_2.0_paper.pdf
Dataset Specification
Number of documents and questions
| Training | Validation | Assessment | Total | |
| Documents | 38,496 | 4,736 | 4,736 | 47,957 |
| Questions | 83,486 | 10,165 | 9,309 | 102,960 |
Ratio of answer types
Categorized according to the length of the answer
Ratio of answer types
| Short | Long | |||
| Text | Choose answer from paragraph | Choose whole paragraph as an answer | ||
| Table | Choose answer from table | Choose whole table as an answer | ||
| List | Choose answer from list | Choose whole list as an answer | ||
Long answer examples
Subtitle repetition (38%)
Q. How was the relationship between Oscar Peterson and Norman Granz formed?
Title. Oscar Peterson – #biography – #Norman Granz
Subtitle variation (47%)
Q. Does Lee have any brothers or sisters?
Title. Lee – #siblings
Creation (15%)
Q. What is the name of the law practiced in order to protect cultural assets?
Title. Volcanic Caves of the Upper Geomunoreum Lava Tube System – #limitedaccess
*Long answers refer to the whole paragraph within the according title.
Short answer examples
Short Answers
Phrase variation (48.0%)
Q. What year did Korea sell bottled water for foreign tourists?
“… around 1988 Seoul Olympics, Korea allowed selling bottled water for foreign tourists, but was prohibited soon after. …
Word variation (15.4%)
Q. What is the name of the field manager of Lotte Chiba who got fired during season in 2009?
“…As the news regarding the dismissal of field manager Bobby Valentine was published, some of the fans…”
Sentence combinations (8.0%)
Q. What is the name of the Korean mobile device manufacturer that used “Don’t Cha” as their commercial music?
“… their debut single “Don’t Cha” ranked number one in the UK, Australia, Canada, etc… Also this song has been used as the commercial music for mobile devices of SKY, a Korean mobile device manufacturer…
Chart/ List
Q. Which party is the second runner-up part of?
- James Earl Carter Jr. (Walter Frederick Mondale) / Democratic / GA, MN
- Gerald Rudolph Ford Jr. (Robert Joseph Dole) / Republican/ MI, KS
- Ronald Wilson Reagan (Robert Joseph Dole) / Republican/ CA, KS
Number of data
100,000 total
Number of participants
1,372 people
Project period
July to August 2019
LG AI & Big Data Research Center
Korean question-answer dataset
Impressive quality of various data
“With Datumo, we were able to efficiently collect KorQuad 2.0, a Question-Answer dataset in Korean. We loved the quality and diversity of data, collected from broad workers. Especially, Datumo’s user guideline for our task was very impressive, capturing our expectations into clear explanations for the workers.”
AI & Big Data Research Center
Collect
Documents from Wikipedia
Create Q&A pairs
Large pool of crowd-workers from Cash Mission*
Validation
Cross-inspection for every single data
*: Datumo’s own developed crowd-sourcing platform which consists of 190K+ crowd-workers.
Process of annotation
KorQuAD 2.0 has been created based on the data collected from Cash Mission. During this process, every crowd-worker was tested to validate their capabilities of forming appropriate MRC questions, before participation. Through our crowd-sourcing platform, we were able to have a variety of participants and ensure consistent data quality by utilizing our unique tutorial system**.
**: Datumo’s tutorial system consists of strict guidelines and tests in order to accurately assess the worker’s understanding of the project.
Collection of documents

- Used Wikipedia to collect structured documents on various topics
- Selected the top 150,000 Wikipedia documents sorted by [Page view] from June 2016 to May 2019, to collect documents that people find interesting
- Added additional 50,000 documents in order to cover a broader range of text domain
Formation of question-answer pairs
- Used Cash Mission, Datumo’s own developed crowd-sourcing platform
- Provided workers with parts of documents instead of the whole article, in order to prevent workers forming Q&A pairs only from the beginning of from “easier” sections (avoid data bias)
- Created Q&A pairs based on the length of the answers – Long/Short
Validation
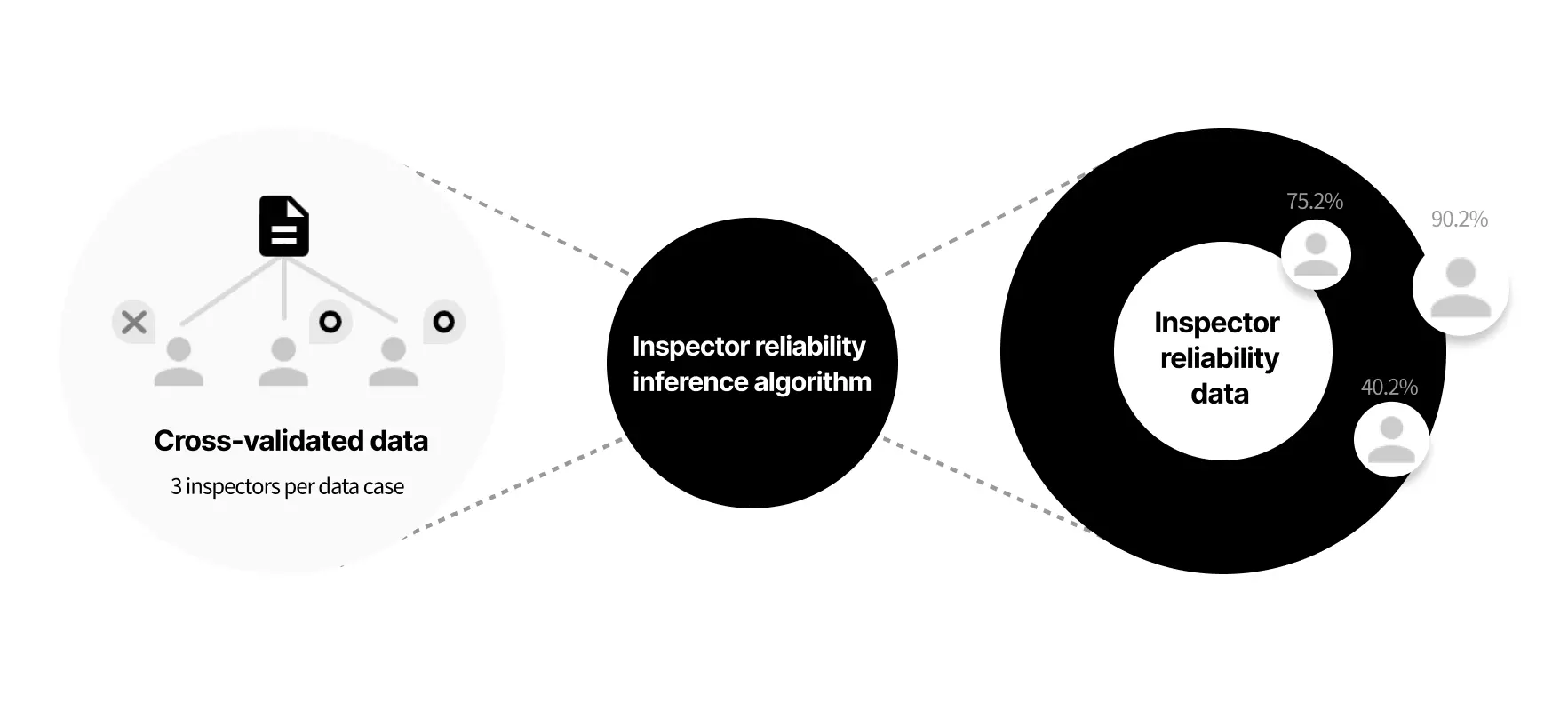
Data quality assurance
- Cross-validation carried out by 2-3 validators, per data
- Disqualified validators with project success rate lower than 85%
Specific guidelines to enhance data quality
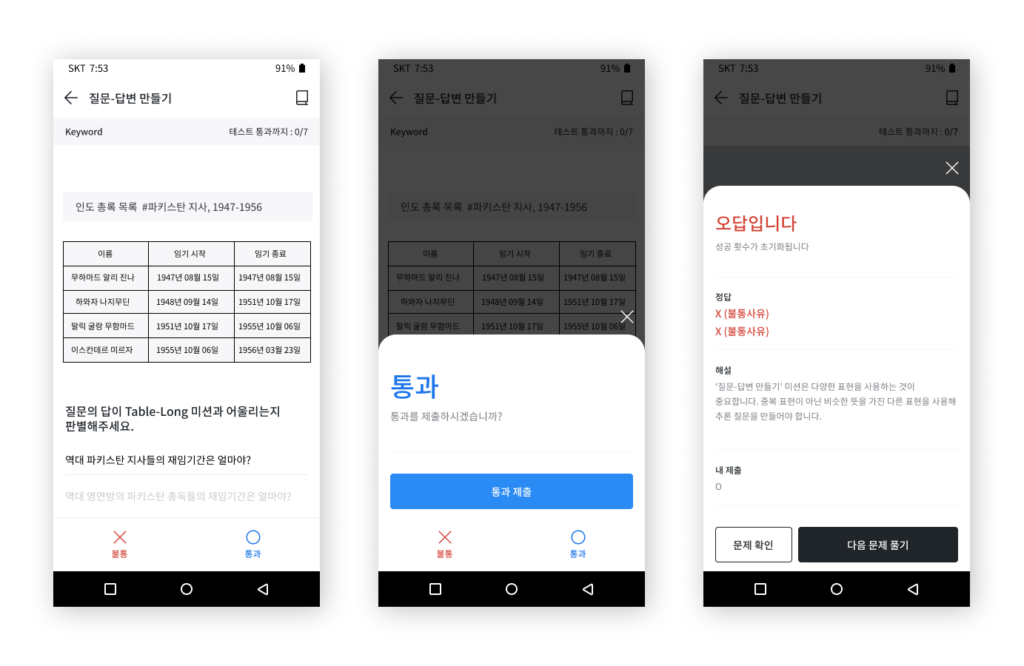
Screenshot of the guideline on Cash Mission
Each and every participant was required to take a test to take part in the actual labeling project. Participants were required to check if the question provided as an example was correct or not, along with their reasons for choosing the answer.
Data to solve pragmatic NLP problems
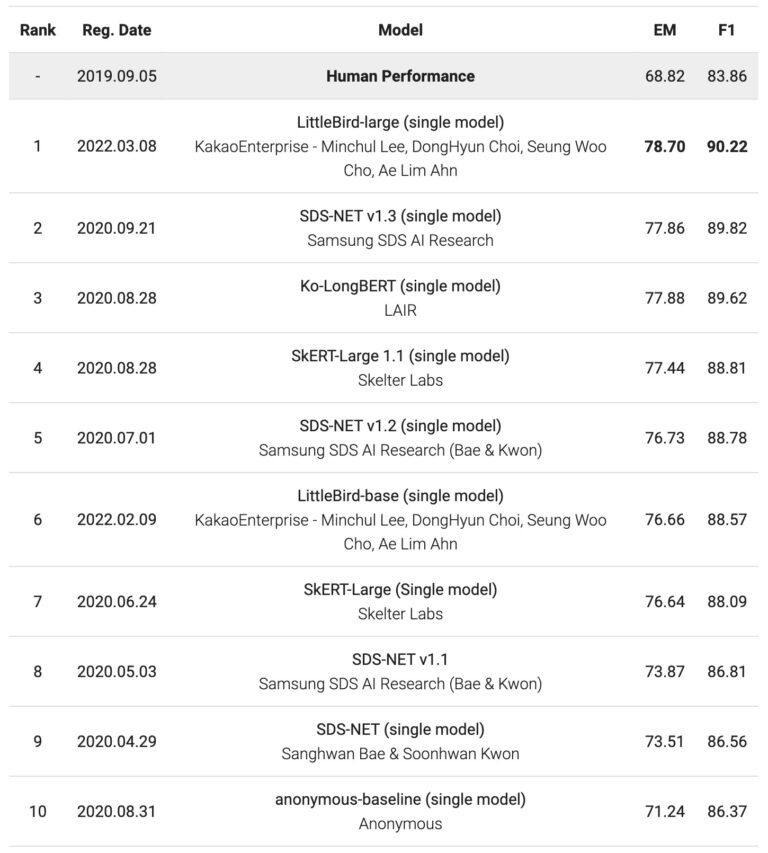
https://korquad.github.io/
KorQuAD 2.0 is currently open to anyone who needs it and is being used to measure the AI model performances of major companies such as Samsung SDS, Kakao, and Naver. It has expanded the range of machine reading from simple sentences to long, complex ones, which solves some of the major issues in the NLP industry. Moreover, as fair evaluation continues, it is founding the basis for developing more effective NLP models.
References
https://korquad.github.io/dataset/KorQuAD_2.0/KorQuAD_2.0_paper.pdf
https://korquad.github.io/