
The assumption that “AI can surpass human capabilities” is no longer surprising. It’s now seen more as a question of when, rather than if. From autonomous driving to programming, AI is quickly catching up to, or even surpassing, human abilities. The latest LLMs demonstrate over 90% accuracy in solving Python coding problems, surpassing human performance in certain tasks.
But can AI-generated code be applied directly in real-world projects? To address this curiosity, a new benchmark, REPOCOD, has emerged. REPOCOD moves away from artificial, simplified code generation tests, focusing instead on assessing AI performance within real project environments.
Limitations of Code Generation Benchmarks
- Reflecting Real Code Completion Tasks: Benchmarks like HumanEval and MBPP mainly include artificially constructed code completion tasks, which don’t fully represent the real coding challenges faced by software developers.
- Including Realistic Task Complexity: Unlike isolated algorithm tests, real development often requires complex context across multiple functions, files, and classes. Existing benchmarks focus primarily on standalone code snippets, missing the project-level context needed to evaluate comprehensive coding skills.
- Reliable Accuracy Evaluation Standards: Many current benchmarks rely on similarity-based metrics to assess model performance. However, while code snippets might look similar, functional accuracy is critical.

Two examples showing misleading metrics results
How is REPOCOD Structured?

Data collection pipeline and instance structure of REPOCOD
Assessing AI's Programming Skills
Now, with the newly structured dataset, it’s time to assess the AI’s actual coding abilities. So, how did it perform? The researchers compared it across various state-of-the-art (SOTA) models and multiple model sizes.
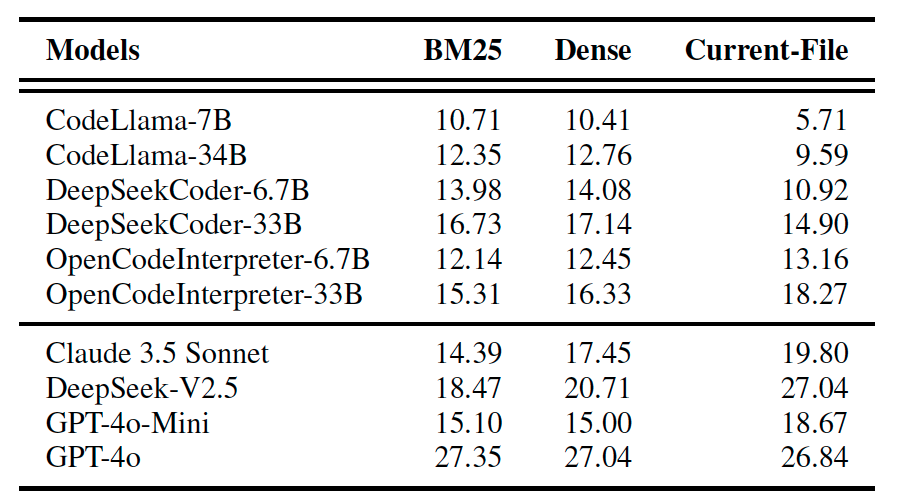
Pass@1(%) of SOTA LLMs on REPOCOD