

Automatic, instant translation from one language to another once seemed like a gimmick straight out of science fiction. Today, machine learning has infiltrated nearly every industry and revolutionized language translation worldwide. What was once a distant dream is now an imperfect but incredibly useful tool.
Machine translation uses artificial intelligence to automatically translate text or speech from one language to another, without human intervention. While the concept may sound straightforward, the reality is far more complex, requiring advanced algorithms, immense processing power, and a deep understanding of language theory.
In recent years, deep learning has revolutionized multiple fields, from biomedical science to marketing, and the machine translation field has followed suit. This article explores how machine translation works, its mechanisms, and its value to individuals and businesses today.
Rule-based machine translation (RBMT)
Rule-based machine translation systems were the first to achieve commercial use. Since language operates within specific rules, RBMT is built on the premise that understanding, mapping, and computing the linguistic rules of two languages allows one to translate between them. These rules can also be edited and refined to enhance translation quality.
RBMT systems analyze the morphological, syntactic, and semantic components of an input sentence in the source language. Based on this analysis, they generate a corresponding output sentence in the target language.
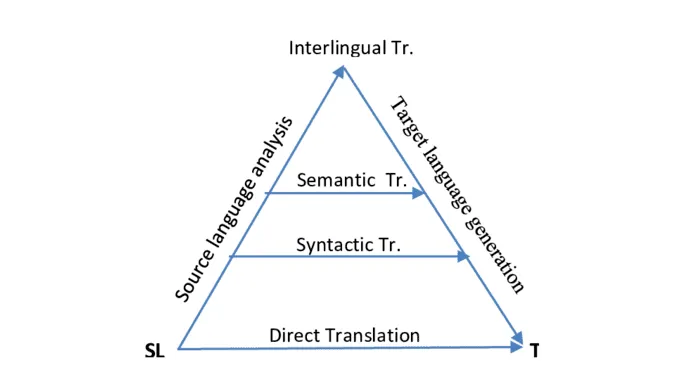
RBMT engines do not require a large, structured set of shared texts to create the system. However, they demand significant human effort to develop the necessary rules and linguistic resources. Debugging these systems is straightforward, as errors can be easily traced to their source during the translation process.
Despite this, RBMT often requires substantial human post-editing. While it provides value in situations where a superficial understanding of meaning is sufficient, the lack of fluency in the output results in an unnatural feel, making it unsuitable for content that demands polished, natural language.
Statistical Machine Translation (SMT)
Words in language are distributed unevenly; some appear frequently, while many are rarely used. Statistical machine translation (SMT) models analyze the numerical relationships between words, phrases, and sentences in both the source and target languages. Using these relationships, SMT converts linguistic elements from one language to another. Some engines enhance this approach by combining statistical and rule-based systems, creating what is known as hybrid MT.
SMT relies on bilingual corpora, collections of text paired with their translations into another language. Machine learning algorithms analyze these corpora alongside target language data, applying probability and information theory to build statistical models. These models use pre-calculated statistical weights to generate translations, prioritizing the most likely equivalents for the source content.

Modern SMT systems prioritize phrases over individual words, translating entire sequences to determine the most likely context for each word. By recording phrase translations and their frequency of occurrence, these systems can handle a degree of ambiguity.
For instance, the German word “pony” can mean a fringe hairstyle or a small farm horse. An SMT model determines the intended meaning by analyzing the frequency of related words in the sentence. If “Bauernhof” (farm) appears, the model is more likely to interpret “pony” as a horse. Conversely, the presence of “Friseursalon” (hair salon) would increase the likelihood of translating it as a hairstyle.

Stay ahead in AI
Neural Machine Translation (NMT)
Deep neural networks have become the dominant paradigm, bringing with them answers to translation problems. NMT uses artificial intelligence to learn languages and, like the neural networks in the human brain, tries to constantly improve that knowledge.
A neural network is a machine learning technique that takes in input data (source language), trains itself to recognize the patterns within the data, and then uses these patterns to predict outputs for a new set of data which is similar in nature to the input data (target language). We discuss neural networks in more detail in another article.
Weight value is assigned to the output of each feature related to their importance in contributing to better translations. Neural networks are trained by processing training examples, one at a time, and updating weights each time, with each update aiming towards a smaller error.
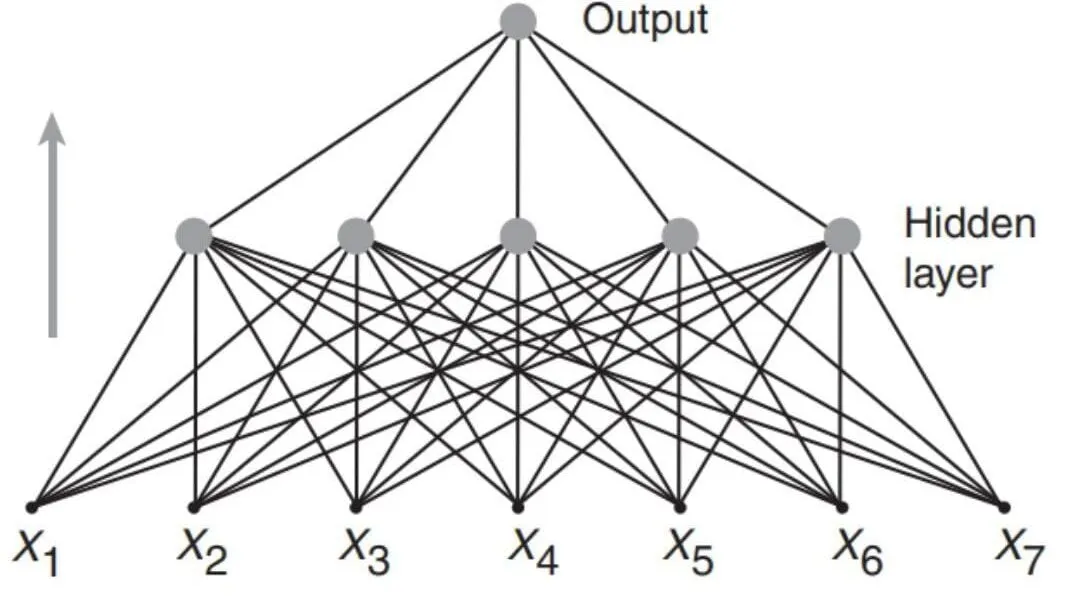
Neural MT is more expensive to train but offers quality unrivaled by the other systems. It is fast, translating millions of words almost instantly, improving its translations with every cycle. MT can handle high-volume translations at speed, and can also work with content management systems to organize and tag that content.
Relying on the large volume of training data and phenomenal computing power, neural MT (NMT) models can analyze information available anywhere in the source sentence and automatically “learn” which feature is useful and at what stage.
It is more accurate, flexible, and easier to add languages. Neural MT is fast becoming the default in MT engine development.
When can machine translation be used?
How useful is machine translation today? Its value is difficult to quantify and highly dependent on your specific needs. For translating large volumes of content, machine translation offers a fast and cost-effective solution. It is particularly well-suited for well-structured, official materials like legal documents or user manuals, but it falls short when applied to creative content such as poems or songs.
Machine translation outpaces human translation in both speed and cost, delivering instantaneous results at a fraction of the price. However, it often struggles with colloquial content like marketing or branding materials, where the output can feel rigid and unnatural. In such cases, human editing is necessary to refine the translations and ensure proper localization.
While machine translation doesn’t need to be flawless to be effective, its imperfections can still provide value. Many companies leverage MT as an initial step in their translation workflow, allowing human editors to polish the results for a more natural and accurate final product.
Are you looking for ways to achieve new efficiencies and remove bottlenecks from your translation process? Used correctly, machine translation expedites your process without compromising on the quality of the output content.
The usefulness of machine translation technology rises with the quality of its data. All machine translation systems demand copious amounts of high-quality data at every step. That amount of data is difficult for an individual or small/medium-sized company to collect while maintaining high quality. It doesn’t stop at collection either. Data preprocessing is made up of laborious processes that require optimal accuracy. Therefore, it is often more ideal to find a service to do it for you.
Here at DATUMO, we crowdsource our tasks to diverse users located globally to provide accurate, ready-to-use data. Moreover, our in-house managers double-check the quality and quantity of the collected or processed data, to ensure a smooth, error-free translation process.


