
Recently, competition among chatbot models has reignited. Models like Bard and Gemini have sparked anticipation with each release, hoping to surpass GPT-4, but they haven’t quite succeeded. However, many claim that the newly released Claude-3 family by Anthropic provides responses far superior to GPT-4. This has led to speculation that OpenAI might soon release a 4.5 version .
While the future remains uncertain, it’s clear that LLMs are continually evolving. Researchers are now seeking new architectures beyond the Transformer-based language model structure and suggesting novel learning methodologies.
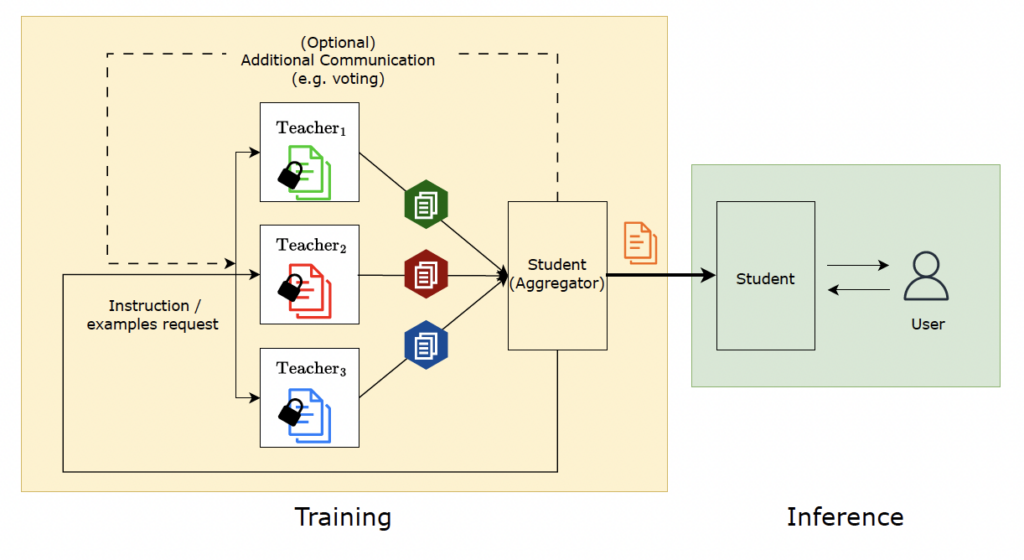
One such recent study is titled Social Learning: Towards Collaborative Learning with Large Language Models. This paper describes a model structure where AI teaches other AI. Let’s delve into how AI collaborates to learn.
Social Learning: AI Teaching AI
This research idea stems from the psychological concept of “Social Learning” by renowned scholar Albert Bandura. Social learning refers to the acquisition of new behaviors or knowledge by observing and imitating others. It’s a natural process for humans, who often learn from media without direct experience. Children, for example, often learn by observing their parents or teachers, which is why adults should be mindful of their behavior around children. Google researchers aimed to apply this social learning theory to LLM learning, enabling LLMs to transfer knowledge to other models.
Understanding the social learning theory makes it easier to grasp the learning structure of the Social Learning model. Researchers assigned AI agents the roles of ‘Teacher’ and ‘Student.’ The teacher agent learns content and transfers it to the student agent, enabling the latter to learn. But if the goal is to create a smart language model, why involve a student agent when the teacher agent already possesses the knowledge?
Disadvantages of Missing Data
There are multiple disadvantages of having missing data in your datasets. Some of the disadvantages are enlisted below:
- Some data science and machine learning tools such as Scikit learn don’t expect your data to have missing values. You have to either remove or somehow handle missing values before you could feed your data to train models from these libraries,
- The data imputation techniques may distort the overall distribution of your data.
Enough of the theory, let’s now see some of the techniques used for handling missing data stored in Pandas dataframes in Python.
Importing and Analysing the Dataset for Missing Values
The dataset that you will be using in this article can be downloaded in the form of a CSV file from the following Kaggle link.
https://www.kaggle.com/code/dansbecker/handling-missing-values/data?select=melb_data.csv
The script below imports the dataset and displays its header.


