
As large language models (LLMs) continue to advance rapidly, efficiently retrieving relevant information from vast amounts of text remains a significant challenge. Traditional retrieval methods tend to focus on small, sequential text fragments. However, they often miss the broader context necessary for comprehensive understanding. RAPTOR, which stands for Recursive Abstractive Processing for Tree-Organized Retrieval, is a new recursive summarization-based retrieval method designed to address this issue. |
A New Approach
The Two Key Retrieval Methods of RAPTOR
RAPTOR’s core retrieval mechanism consists of two main methods: Tree Traversal Retrieval and Collapsed Tree Retrieval. These two approaches allow RAPTOR to efficiently locate information within documents, each offering distinct advantages.
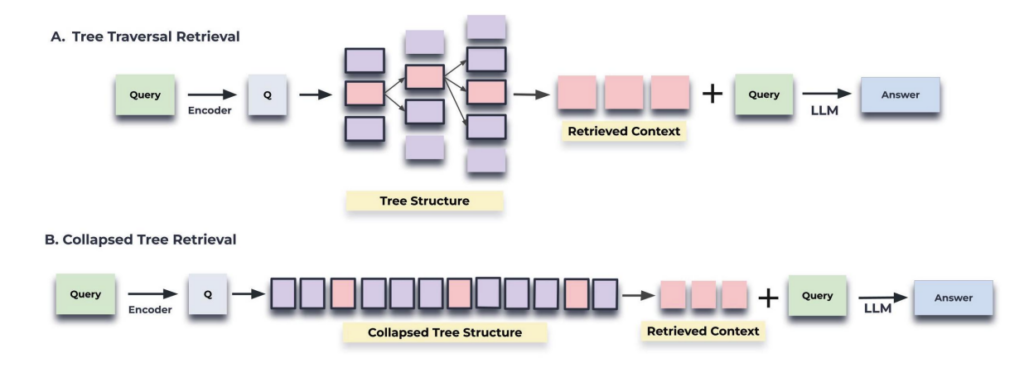
RAPTOR's Two Mechanisms.
1. Tree Traversal Retrieval
The Tree Traversal Retrieval method involves RAPTOR navigating the hierarchical tree structure it creates, starting from the root and sequentially exploring lower levels. This approach calculates the similarity between the query and the root node, first assessing higher-level concepts, then exploring child nodes one by one to ultimately deliver search results.
- How it works: Starting at the root, RAPTOR selects the most similar node at each layer and gradually moves down to the lower levels, refining the information. The selected nodes at each layer contain the information most relevant to the query.
- Advantages: This method is ideal for grasping the big picture of a document before drilling down into finer details. It gradually explores from broader concepts to specific information.
- Disadvantages: Since the traversal is sequential, it may struggle to simultaneously consider both detailed information and higher-level concepts that a query might require.
2. Collapsed Tree Retrieval
The Collapsed Tree Retrieval method flattens all layers of the tree, allowing RAPTOR to evaluate all nodes at once. This approach does not rely on a specific layer of the tree, enabling it to extract relevant information from multiple levels simultaneously.
- How it works: RAPTOR flattens the tree and calculates cosine similarity for all nodes, selecting those most similar to the query. The selected nodes contain a mix of high-level concepts and detailed information, pulling data from various layers at once.
- Advantages: Since it evaluates multiple layers simultaneously, this method flexibly combines detailed information with higher-level summaries, providing results that are well-suited to the query.
- Disadvantages: Evaluating every node in the tree can be computationally expensive, but RAPTOR addresses this issue by utilizing fast retrieval libraries like FAISS to optimize the process.
How is it different from traditional methods?
In traditional top-k retrieval methods, the system simply selects the top-k most similar text segments based on the query. While this approach is fast and effective for finding the most relevant segments, it is limited to retrieving information within a fixed range, which makes it difficult to provide integrated information across different layers of a document. In contrast, Collapsed Tree Retrieval searches across all layers of the tree simultaneously, offering more complex and flexible search results. RAPTOR’s collapsed tree retrieval consistently outperformed traditional top-k retrieval in experiments on 20 stories from the QASPER dataset. It achieved the best performance when searching for the top 20 nodes containing up to 2,000 tokens, thanks to its ability to balance detailed information with higher-level summaries. This demonstrates how RAPTOR enables multi-layered information integration and efficient search, something that traditional systems struggle to provide. |
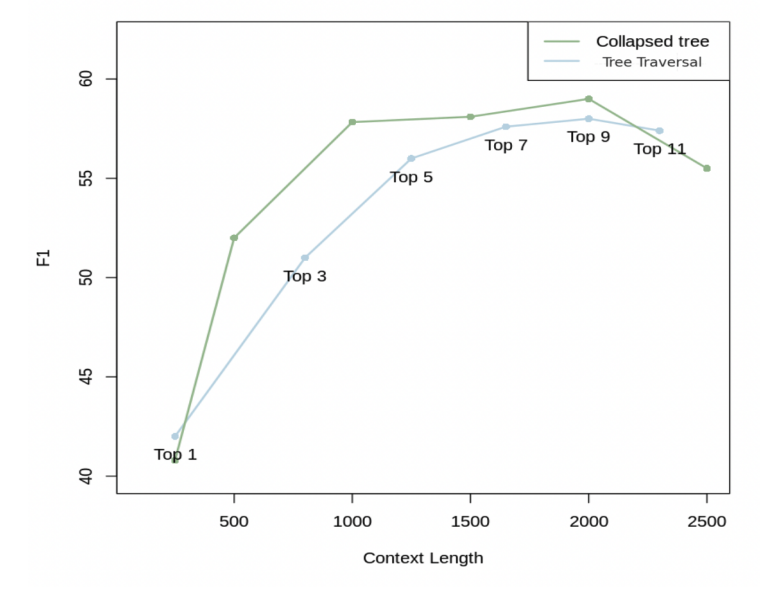
Comparison of various top-k tree searches and Collapsed Tree Retrieval on the QASPER dataset.
Innovations in Tree-Based Retrieval Systems
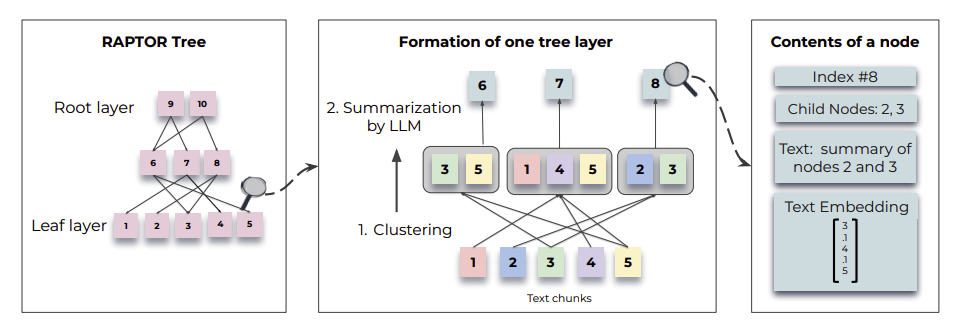
RAPTOR's tree construction process.
Thanks to its tree structure, RAPTOR excels in handling complex documents. In particular, on the QASPER dataset, RAPTOR achieved an F1 score of 55.7%, a measure that balances precision and recall. This surpasses the previous best performance of 53.9% by CoLT5. These results demonstrate RAPTOR’s ability to effectively integrate details and overarching themes in complex documents, such as scientific papers, allowing it to retrieve accurate information with minimal error.
Why is this research important?
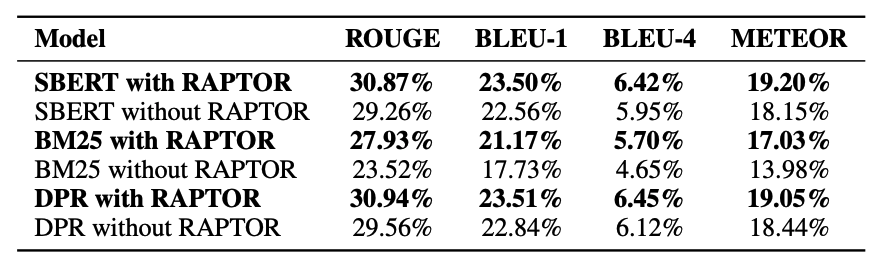
Performance comparison across the QuALITY and QASPER datasets.
In the NarrativeQA dataset, SBERT, BM25, and DPR, when combined with RAPTOR, all demonstrated higher ROUGE-L scores compared to when they were used independently. Notably, the combination of BM25 and RAPTOR improved performance from 23.52% to 27.93%, while DPR combined with RAPTOR achieved the highest score at 30.94%. This clearly demonstrates that RAPTOR consistently enhances retrieval accuracy when paired with various search methods.


