
Welcome to Part 2 of our GraphRAG tech series.
In our previous letter, we explored why GraphRAG is needed and broke down its core architecture. Today, we’ll take a closer look at two key components in the GraphRAG design flow: the Query Processor and Graph-Based Retrieval.
These elements play a key role in working with structured data effectively, and a clear understanding of how they function is essential for developing AI systems that are more intelligent and context-aware.
From Similarity to Structure
Traditional RAG systems embed questions like “Who is Steve Jobs’ brother?” and retrieve relevant information by calculating similarity with document vectors. GraphRAG, on the other hand, goes beyond simple similarity-based retrieval by navigating information through relationships and structure. At the heart of this process are the Query Processor and Retriever stages, which determine how the question is interpreted and how the system searches within the graph.
1. Query Processor
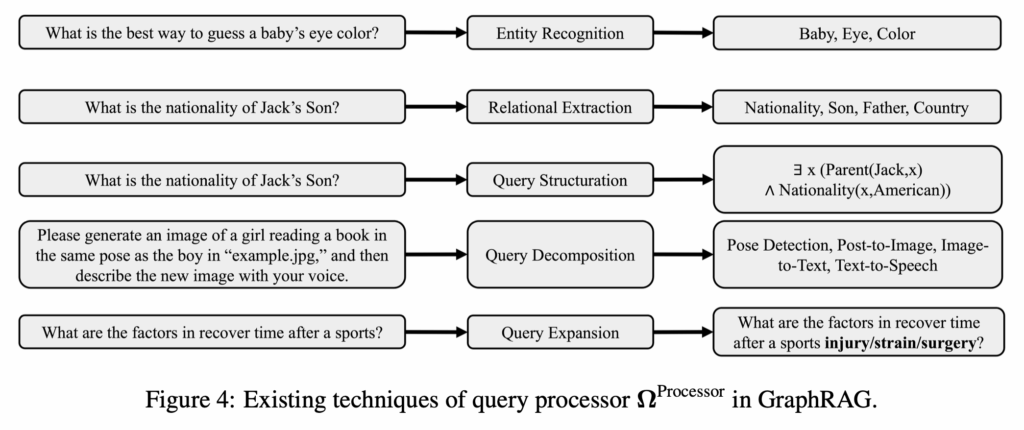
In GraphRAG, the Query Processor transforms natural language queries into forms that can be effectively used to navigate a graph. This goes beyond simple keyword matching, requiring structured interpretation of the question. Let’s take a closer look at five core techniques used in this process. 🔎
Named Entity Recognition (NER)
Identifies people, places, and named entities within a question. Unlike traditional RAG, which extracts entities from unstructured text, GraphRAG must match them to nodes within a graph.
► Example: “Who is Steve Jobs’ brother?” → Locate the ‘Steve Jobs’ node within the graph.Relation Extraction
Detects relationships between entities mentioned in the query. These are represented as edges in the graph and are essential for accurate interpretation.
► Example: “Who is his brother?” → Map the relationship to a sibling_of edge in the graph.Query Structuration
Converts natural language into graph query languages like Cypher, SPARQL, or GQL. This is especially useful for exploring complex connections, and automated structuring using LLMs is an area of active research.Query Decomposition
Breaks down complex queries into multiple, logically connected sub-queries.
► Example: “Who among A’s friends likes B?” → Split into steps that explore friendships and preferences across nodes.Query Expansion
Expands the scope of the query to include related but unstated nodes or relationships.
► Example: “What company did he start?” → Use nearby nodes in the graph to resolve who “he” refers to and enrich the query.
These techniques are often combined, not used in isolation. Together, they enhance the structural precision of the query and improve the accuracy of graph-based retrieval.
Source: Retrieval-Augmented Generation with Graphs (GraphRAG)

Stay ahead in AI
2. Retriever
1. Graph Traversal-Based Retrieval
GraphRAG can perform direct traversal within the graph structure, starting from nodes relevant to the query. Common techniques include path-based strategies like Breadth-First Search (BFS), Depth-First Search (DFS), and Monte Carlo Tree Search (MCTS). The traversal scope is typically defined by l-hop neighborhoods or specific relationship paths.
2. GNN-Based Embedding Retrieval
To capture both structural patterns and node-level features, Graph Neural Networks (GNNs) are used to generate context-aware embeddings. These embeddings incorporate information from each node’s neighbors, enabling similarity calculations that reflect both content and position in the graph.


