
Retrieval-Augmented Generation (RAG) is one of the most widely adopted methods for improving the factual accuracy of generative AI. The approach augments LLM responses by retrieving relevant context from external sources before generating an answer. Typically, this retrieval is based on text similarity, and the method has already been deployed across many real-world applications.
But what happens when the data isn’t just text?
Recommendation systems with users, items, and interactions
Document graphs with papers, authors, and citation structures
Biomedical data connecting genes, proteins, drugs, and diseases
Organizational charts, API call graphs, or financial networks
In these cases, where understanding structure and relationships is key, traditional RAG falls short. Let’s take a look at GraphRAG, a concept designed to address these limitations.
The Basics
GraphRAG begins with a clear motivation:
Graphs are powerful tools for representing complex relationships,
but traditional RAG can’t fully leverage them.
While classic RAG operates on similarity-based retrieval of unstructured text, incorporating graph data requires fundamentally different design principles. GraphRAG addresses this by introducing structured reasoning, multi-hop traversal, and graph-informed generation. Its architecture can be distilled into five core components:
1. Query Processor
This component interprets the user’s natural language query into a graph-based form. For example, when asked “Who is Steve Jobs’ brother?”, the system identifies the entity (“Steve Jobs”) and the relation (“sibling”) to formulate a structured query. It involves entity recognition, relation extraction, and query formalization tailored for graph traversal.
2. Retriever
Unlike traditional embedding-based search, GraphRAG performs relation-aware, multi-hop retrieval. Based on the processed query, it navigates the graph to retrieve relevant nodes(entities), edges(relationships), and subgraphs that hold contextual relevance to the question.
3. Organizer
The retrieved graph data is often too large and intricate for direct input into an LLM. The Organizer filters, compresses, and restructures the graph data, ensuring it fits within token limits and aligns with the model’s attention capabilities. The goal is to preserve essential context while reducing noise.
4. Generator
Using the cleaned and structured graph data, the LLM generates a natural language response. This stage integrates relational context and structural cues into the answer, often by translating the graph into a prompt-compatible format. The model isn’t just summarizing facts. It’s reasoning through relationships.
5. Graph Data Source
This is the backbone of the entire system. Depending on the domain, GraphRAG draws from different types of structured data: knowledge graphs(e.g., Wikidata), citation networks in academic literature, biological interaction graphs(e.g., gene-disease networks), and more. Each source has its own schema and integration requirements.
By combining structured retrieval with natural language generation, GraphRAG extends RAG from a simple text matching tool to a robust framework capable of understanding and generating answers from highly relational data.

Stay ahead in AI
Beyond RAG: Why GraphRAG Matters
Traditional RAG systems are built on the assumption that data comes in uniform structures like 1D text sequences or 2D image grids. This works well for many applications, but it falls short when the information landscape becomes more complex.
GraphRAG extends RAG by operating on graph-structured data, which naturally represents intricate relationships across nodes and entities. Unlike conventional RAG, which relies heavily on vector similarity, GraphRAG leverages the topology of the graph itself—factoring in traversal paths, node connectivity, and domain-specific structures.

At a glance, the transition may seem like a mere architectural tweak. In reality, it’s a fundamental shift. You can’t just plug graph data into a standard RAG pipeline. The underlying assumptions, query logic, and inference mechanisms need to be rethought from the ground up.
Take this example:“What drugs are associated with the EZH2 gene?”
This isn’t a matter of simple keyword similarity. It requires understanding relationships like [Gene → Target Relationship → Drug]. GraphRAG is designed to follow these relational paths, allowing the system to infer answers that go beyond surface-level matches.
In short, while RAG excels at retrieving relevant chunks from flat knowledge bases, GraphRAG brings in the power of structured reasoning, which is especially critical in domains like biomedical research, knowledge graphs, and beyond.
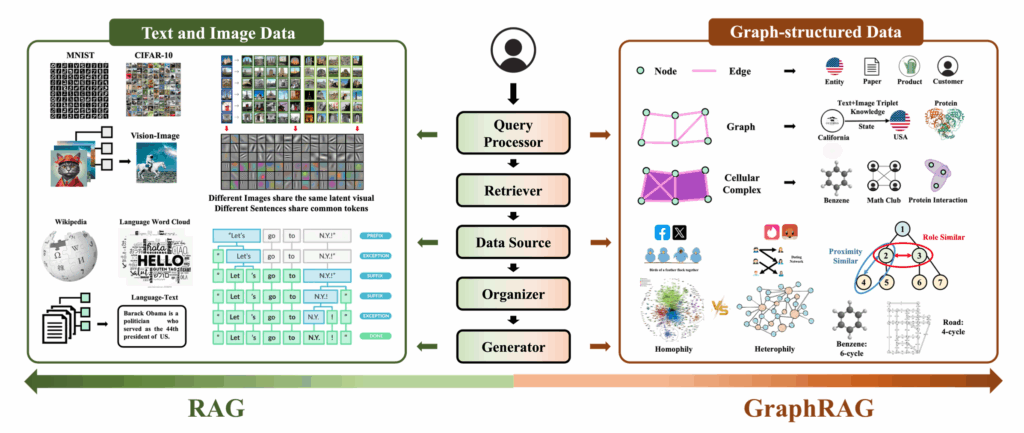
Source: Retrieval-Augmented Generation with Graphs (GraphRAG)
Why GraphRAG Is Gaining Attention
LLMs excel at generating fluent, natural language. But when it comes to trustworthiness, they still face critical challenges, such as outdated information, factual inconsistencies, and unclear sourcing. And as we’ve seen, real-world data is often far more complex than simple sequences. It’s relational and deeply structured. This is where GraphRAG comes in.
GraphRAG addresses the limitations of traditional RAG systems, which rely heavily on textual similarity, by:
Directly operating on domain-specific graph structures(e.g., molecules, documents, social networks)
Searching and generating content with relational and structural awareness
Using a graph-native architecture that integrates with LLMs seamlessly
One of GraphRAG’s greatest strengths is its flexibility across domains—each of which has unique structural characteristics that can’t be handled with a one-size-fits-all approach:
Molecular graphs require understanding 3D geometry and chemical bonding.
Recommendation systems depend on modeling user relationships and behavioral flows.
Document graphs demand awareness of citation and reference networks.
GraphRAG represents a new paradigm in AI system design—one that goes beyond RAG’s embedding-based approach to embrace the richness of relational data. To explore and reason over these complex connections effectively, we need smarter frameworks. GraphRAG points us in that direction.
Today, we took a high-level look at what GraphRAG is, why it matters, and how it’s architected. In the next edition, we’ll dive into two of its most critical components: Query Processing and Retrieval Design.
We’ll explore how natural language queries are mapped to graph traversals, and how structure-aware retrieval differs from traditional methods.


