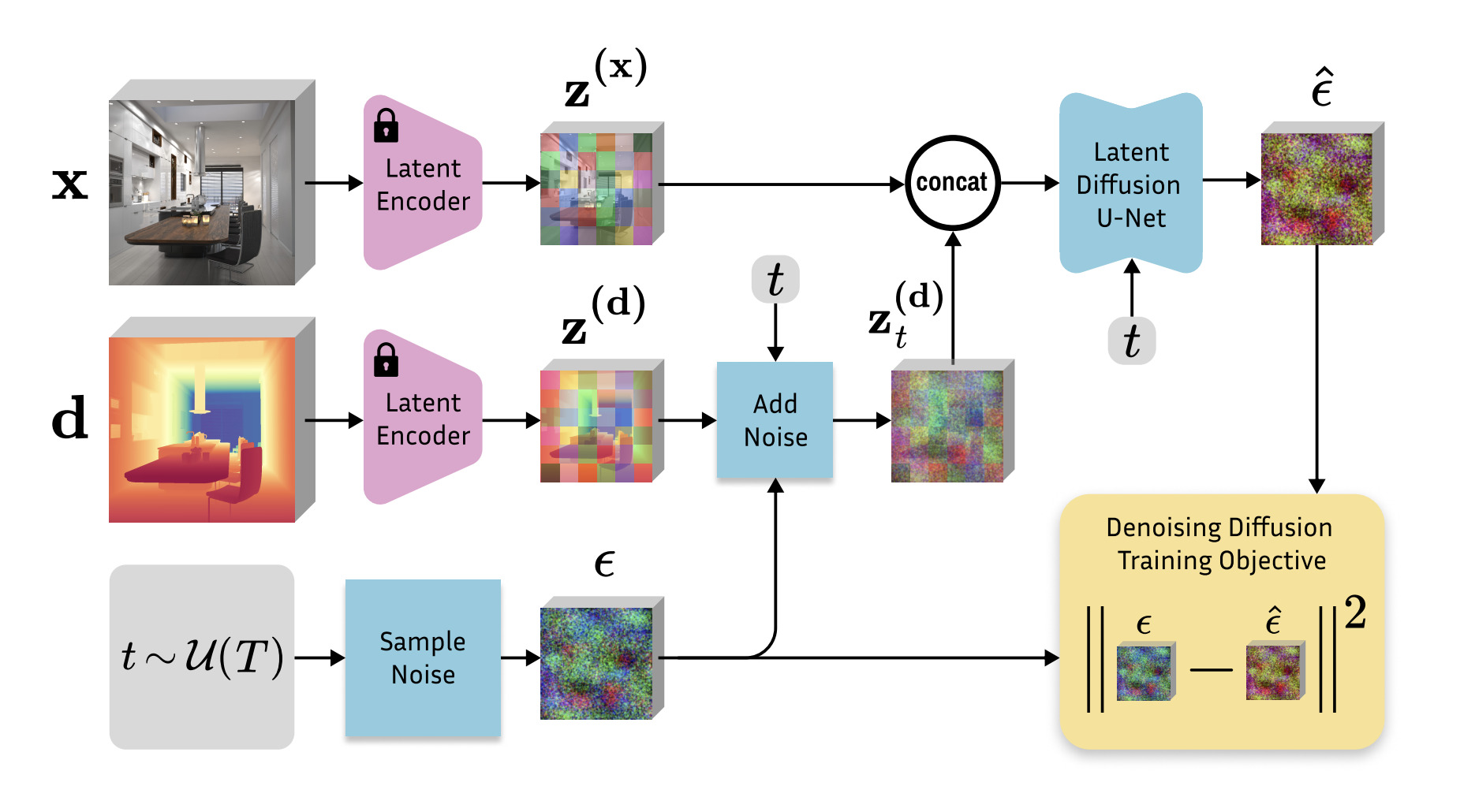
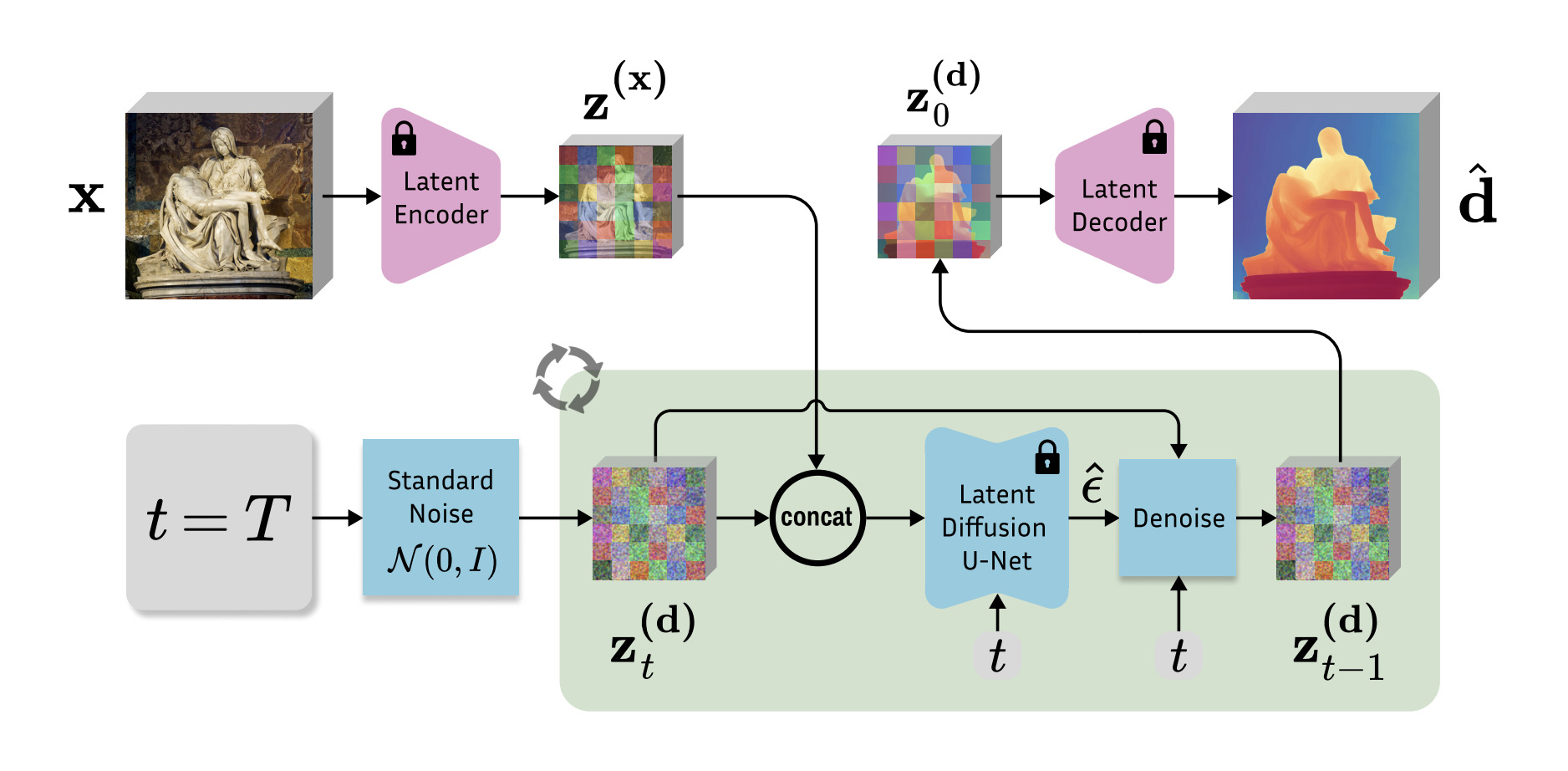
Marigold focuses on monocular depth estimation, meaning it can generate a depth map from a single 2D image. To achieve this, a significant amount of information must be accumulated, including experiential data about objects in the image, segmentation between objects, separation of objects from the background, and relative depth perception based on visual size.
The Marigold model was introduced in the paper Marigold: Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation, published in December 2023. Marigold is unlike traditional methods. It integrates diffusion-based models, typically used for image generation, into the field of depth estimation. The researchers’ idea was as follows:
If image generation models have already learned high-quality images from various domains uploaded to the internet, could this be applied to depth estimation?
Thus, Marigold leverages the pre-trained capabilities of Stable Diffusion. To adapt this generative model for depth estimation, fine-tuning is required.