
2. Scraping Reddit using Reddit API
We will be scraping donation requests made on Reddit by using the official Reddit API. To access it, you need to:
- Go to the official Reddit website
- Log into your Reddit account or create a new one
- Go to User Settings
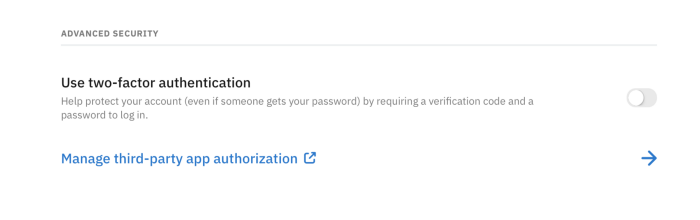
4. Go to Privacy and Security
5. Go to App authorization
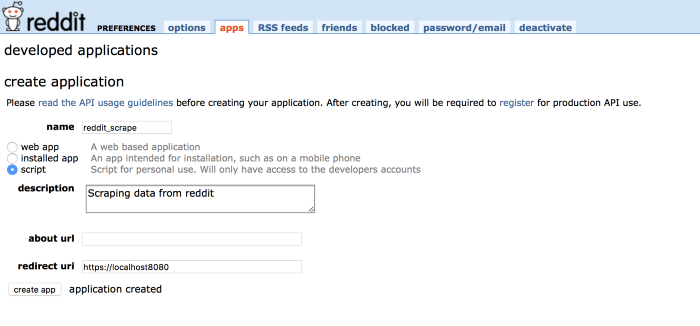
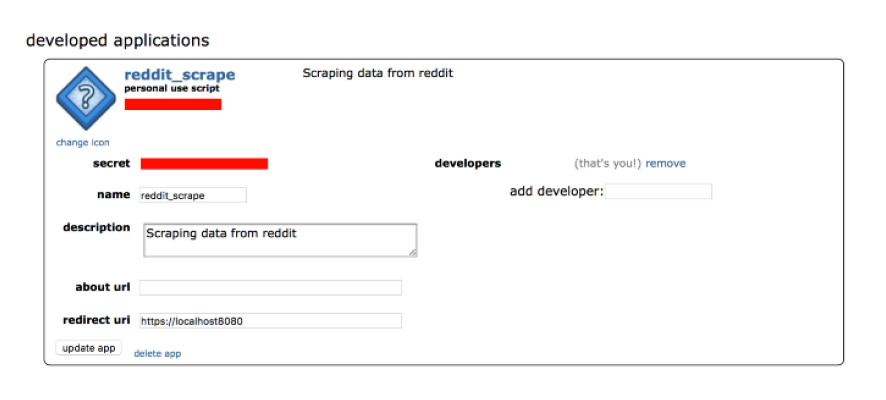
7. Create a name for your application and fill in the other relevant credentials. In redirect URL, put the URL of your localhost.
8, Click on ‘create app’
Installations
We will be using a Python framework named Praw to easily use the Reddit API. To install it, run the following command in your terminal:
pip install praw
Python Code
import praw
import pandas as pd
import numpy as np
# Fill in your own credentials for client_id, client_secret and user_agent. Characters in'Personal use script' make your client_id, those in 'secret' make client_secret and user_agent is the name of your application.
reddit = praw.Reddit(client_id = '',
client_secret = '',
user_agent = '')
# Get posts from the subreddits related to donations
hot_post_1 = reddit.subreddit ('donate').hot(limit = 10)
hot_post_2 = reddit.subreddit ('Assistance').hot(limit = 10) # Offers
hot_post_3 = reddit.subreddit ('Charity').hot(limit = 10)
hot_post_4 = reddit.subreddit ('Donation').hot(limit = 10)
hot_post_5 = reddit.subreddit ('gofundme').hot(limit = 10) # lots of categories
hot_post_6 = reddit.subreddit ('RandomKindness').hot(limit = 10)
hot_post_7 = reddit.subreddit ('donationrequest').hot(limit = 10 )
# Saving donation posts in an empty list
posts = []
for post in hot_post_1:
posts.append ([post.title, post.score, post.id, post.subreddit, post.url, post.num_comments, post.selftext, post.created])
for post in hot_post_2:
posts.append ([post.title, post.score, post.id, post.subreddit, post.url, post.num_comments, post.selftext, post.created])
for post in hot_post_3:
posts.append ([post.title, post.score, post.id, post.subreddit, post.url, post.num_comments, post.selftext, post.created])
for post in hot_post_4:
posts.append ([post.title, post.score, post.id, post.subreddit, post.url, post.num_comments, post.selftext, post.created])
for post in hot_post_5:
posts.append ([post.title, post.score, post.id, post.subreddit, post.url, post.num_comments, post.selftext, post.created])
for post in hot_post_6:
posts.append ([post.title, post.score, post.id, post.subreddit, post.url, post.num_comments, post.selftext, post.created])
posts = pd.DataFrame (posts, columns = ['title', 'score', 'id', 'subreddit', 'url', 'num_comments', 'body', 'created'])
#posts
df = pd.DataFrame (data = posts)
dataframe = df.to_csv (r'donations.csv', index = False)
# Data Processing
df = pd.read_csv ('donations.csv')
df = df.drop (['id', 'subreddit', 'num_comments', 'url', 'created'],1)
df = df[['title', 'score','body']]
print (df.head ())
print(df.shape)
# Saving donation posts to a csv file
dataframe = df.to_csv (r'donations.csv', index = False)
Output:

3. Scraping contents of a web page
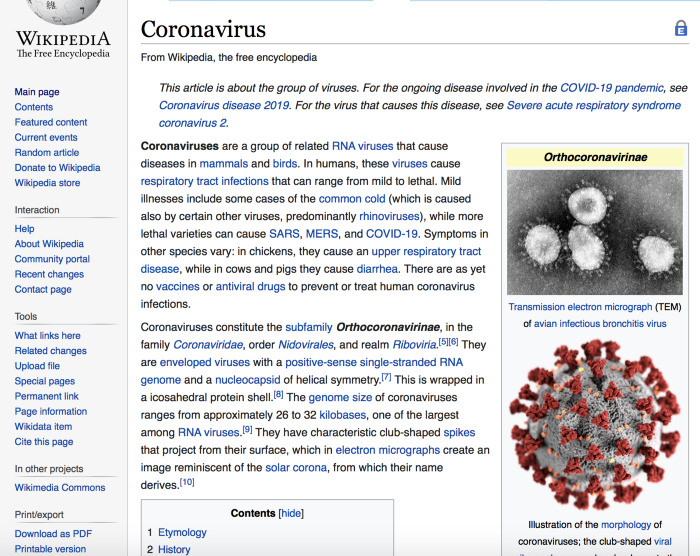
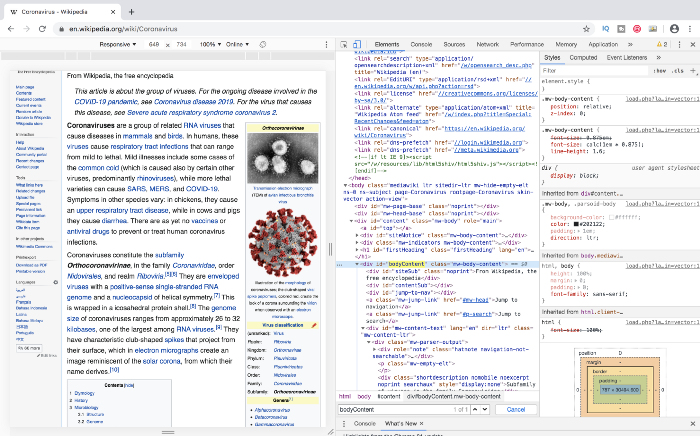
We will be scraping the text content of a Wikipedia page about Reddit using a simple and powerful Python library named BeautifulSoup. It is also important for you to be familiar with some of the basics of HTML for web scraping. First, right-click and open your browser’s inspector to inspect the webpage. Hover your cursor on the desired section whose content you want to scrape, and you should be able to see a blue box surrounding it. If you click it, the related HTML will be selected in the browser console. The section that we wish to scrape is a div that contains the entire text within the page.
Installations
To install BeautifulSoup, run the following command in your terminal:
pip install BeautifulSoup4
Python Code
# import libraries
import urllib
from bs4 import BeautifulSoup
# specify url of webpage whose content you need to scrape
url = "https://en.wikipedia.org/wiki/Coronavirus"
request = urllib.request.Request (url)
# query the website and return the html of the webpage
response = urllib.request.urlopen (request)
# parse the html using beautiful soup
var = BeautifulSoup (response,'html.parser')
# Take out the <div> and get its value
text_box = var.find ('div', attrs = {'id': 'bodyContent'})
text = text_box.text.strip ()
print (text)
Output:
From Wikipedia, the free encyclopedia Jump to navigation Jump to search This article is about the group of viruses. For the ongoing disease involved in the COVID-19 pandemic, see Coronavirus disease 2019. For the virus that causes this disease, see Severe acute respiratory syndrome coronavirus 2. Subfamily of viruses in the family Coronaviridae Orthocoronavirinae Transmission electron micrograph (TEM) of avian infectious bronchitis virus Illustration of the morphology of coronaviruses; the club-shaped viral spike peplomers, colored red, create the look of a corona surrounding the virion when observed with an electron microscope.
4. Scraping images
We will be scraping images in batch through the Fatkun Batch Download Image extension.
Prerequisites
You will be needing Google Chrome Browser along with Fatkun Batch Download Image extension.
Steps:
- After you are finished with the installation, search for the website and the pictures that you want to download
- Click on the extension’s icon
- Now an extension will get opened which would display a new tab showing all images that have been detected by it. All the pictures that appear on the extension’s tab by default have opted for the purpose of download. After making the choice, click on ‘save image’.
- The extension would now provide you with the warning and will ask where to save the file before it is being downloaded and you have to give the confirmation for each image.
- The extension would create for you a new folder based on the title of the website and there you could download all the desired images. You could even click on ‘more options’ so that with the aid of link you could simply filter the images, rename and sort them as per size.
While crawling presents easy access to many web-based data collections, most times, such data also accompanies heavy noises and contaminations to be used as a dataset right away. Therefore, companies or researchers need to devote heavy efforts in quality controlling; having enough human resources is always a great challenge. Therefore, it is often more efficient to find another service that does laborious works (including both collection and preprocessing) for you. For that, we could be your perfect solution!
Here at DATUMO, we crowdsource our tasks to diverse users located globally to ensure the quality and quantity simultaneously. Moreover, our in-house managers double-check the quality of the collected or processed data! Check us out at datumo.com for more information!


