
Learn how modern speech recognition algorithms like wav2vec can potentially recognize all languages in the world
Many AI researchers believe that we are decades away from achieving Artificial General Intelligence (AGI) or true human-like intelligence. Though far away, recent advancements in computer vision, generative modeling, natural language processing, and speech recognition have brought us closer to realizing AGI in the near future.
Efforts to improve the natural language understanding of computers go back to the 1950s. Today, automatic speech recognition (ASR) models can recognize many languages–limited only by the availability of more diverse language datasets.
Existing speech recognition techniques require curated language datasets with hours of clean audio accompanied by transcribed text. Speech recognition models are trained on these datasets to learn language-specific representations. But what if a speech recognition model trained for English or French receives audio input of lesser-known languages like Tartar or Swahili?
They will fail miserably or produce gibberish. So, we need more inclusivity in AI speech recognition systems.
With more than [7000 languages] spoken worldwide, it is impossible to curate high-quality audio datasets and scale speech recognition systems for each of them. Researchers at Meta introduced an unsupervised speech recognition approach called wav2vec-unsupervised (wav2vec-U) that does not require any labeled audio datasets.
In this post, we’ll take a deep dive into understanding unsupervised speech recognition and the wav2vec-U model and how it compares with existing supervised speech recognition approaches.
What is Unsupervised Speech Recognition?
Unsupervised speech recognition is an AI technique that trains speech recognition systems without any labeled audio data, eliminating the need for transcribed text. Without transcribed text, audio waveforms are directly fed into unsupervised models, where they are processed and converted to text. It is the key to unlocking inclusivity and diversity for speech recognition systems.
Unsupervised wav2Vec Architecture Explained
wav2vec-U requires no transcribed speech data as it learns purely from unlabeled audio. It is built on top of a self-supervised wav2vec 2.0 model and a generative adversarial network (GAN). Let’s discuss these two components in detail:
1. Self-Supervised wav2vec 2.0
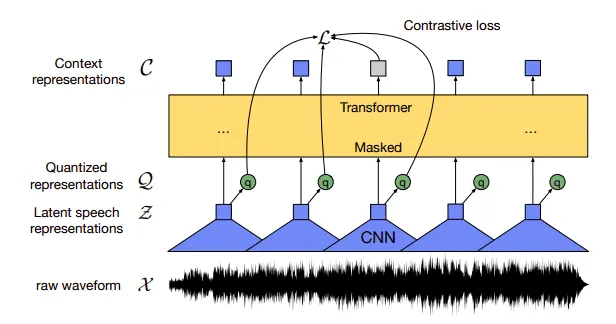
wav2vec 2.0 architecture for learning contextual audio representations. Image by Meta AI
Speech data is a continuous signal without any clear and discrete audio segments. The goal of wav2vec 2.0 is to learn discrete contextual speech representations from unlabeled audio. Modern ASR systems can perform better speech recognition for various languages using these contextual speech representations.
First, the raw audio waveform for any language is passed through a multilayer Convolutional Neural Network (CNN) feature encoder to obtain discrete latent speech units that are 25ms long.
The speech units are then passed through a quantization module using the product quantization technique to map speech units more accurately to their learned audio representations.
Finally, the quantized speech representations are passed to a transformer encoder where about 50% of the audio is masked to initiate self-supervision. Using a contrastive learning approach, the transformer predicts these masked representations in the audio signal.
Over time, the self-supervised model improves and learns more accurate high-level contextual speech representations from the input audio. The self-supervised output model better understands what human voice sounds like and is ready for speech recognition.
2. Generative Adversarial Network (GAN)
The output of the pre-trained self-supervised wav2vec2.0 model is passed to a GAN that has a generator and a discriminator neural network.
At first, the generator outputs non-sensical transcription from the self-supervised input speech representations. The output transcriptions of the generator are phonemes which are distinct units of sound corresponding to the sound in the input language.
The output phonemes are fed into the discriminator to improve transcriptions, which decides whether the generated text is good or makes sense at all.
The discriminator compares these phonemes with real language text and gives feedback to the generator to improve transcriptions. This process is repeated numerous times until the generator transcriptions resemble real language text.
Adding a GAN system enables unsupervised speech recognition, eliminating the need for any annotated speech data at all.
How Unsupervised Speech Recognition Compares With Supervised Approach
The wav2vec-U model shows favorable results compared to state-of-the-art supervised and unsupervised speech recognition models.
For unsupervised speech recognition, wav2vec-U shows 57% less phoneme error rate (PER) compared to the next best unsupervised speech recognition model. For supervised learning, existing speech recognition models use hundreds of hours of labeled speech data. However, wav2vec-U performs at par with some of the best supervised speech recognition models without any annotated audio.
wav2vec-U clearly demonstrates the ability to build versatile speech recognition models solely from unlabeled raw audio, enabling AI researchers to develop better speech systems with less effort.
Limitations of Unsupervised Speech Recognition
Unsupervised speech recognition is made possible after years of efforts and improvements in exiting speech recognition, self-supervision, and unsupervised machine translation techniques. But, there are a few minor limitations, including:
1. Developing Better Multi-Language Phonemizers
wav2vec-U enables cross-lingual training where a single model can recognize multiple languages. It can generate phonemes that overlap with multiple languages which sound alike. This technique can be further improved to include more languages in the future.
2. Generalizing Phonemizers
Using generative modeling, researchers can generate more generalized phonemes to enable more inclusive speech recognition.
3. Improving Audio Segmentation Techniques
In supervised speech recognition, audio waveforms are paired with corresponding transcribed text, which can be directly given as input to an ASR system. However, in unsupervised learning, the raw audio waveform must be converted into smaller audio segments or speech units. By improving audio segmentation techniques, modern ASR systems can become more powerful.
4. Learning Variable-Sized Contextual Representations
The current unsupervised wav2vec-based speech recognition enables character-based learning. To improve the power of unsupervised models, researchers can experiment with variable-sized audio representations.
5. Curating Datasets for Low-Resource Languages
We need curated datasets for labeled and unlabeled speech audio to develop the next-generation ASR systems that can work for any language. Particularly, in the case of rare languages where even unlabeled speech audio is not available, researchers find it difficult to develop robust speech systems.
Power Your Speech Recognition Applications With Highly Curated Speech Data
Speech recognition is continuously advancing with newer techniques and more robust AI systems. Unsupervised speech recognition has opened up many opportunities for building leading-edge speech recognition systems. While researchers are still scratching the surface with unsupervised learning, curating more labeled and unlabeled speech datasets wouldn’t hurt.
DATUMO is a leading crowdsourcing platform that enables quick and accurate data collection and annotation for audio, video, image, and text data. Our highly-trained crowdsource workers can diligently tag, edit, classify, segment, and transcribe data as per your needs. Contact us today and start curating high-quality datasets to fuel your speech recognition applications.


