
One of the most effective methods for reducing hallucinations in language models is generating answers based on search results, and a prime example of this is RAG. RAG, or Retrieval-Augmented Generation, involves using search-augmented generation techniques, where the language model uses search results as input when generating answers to questions. It’s akin to searching for information on a portal site when you’re curious about something.
For RAG to work effectively, it’s crucial to find the right documents related to the query. While leveraging a well-established search engine is an option, it’s not always feasible. For example, company-owned data or highly specialized information might not be available through search engines. In such cases, a separate database must be created, and only the information related to the query should be filtered.
So, how do we filter similar information? First, we need to calculate the similarity between the search query and the documents in the database. This requires vectorizing each document, a process known as Embedding.
Embedding
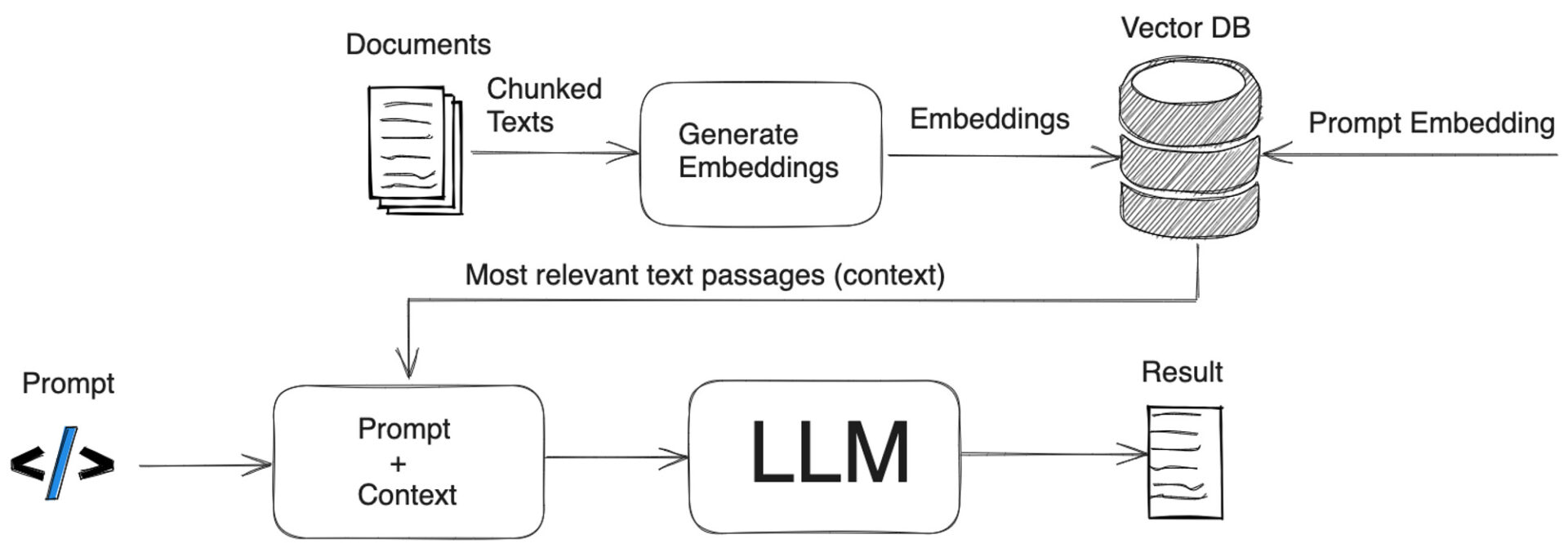
Source: A Gentle Introduction to Retrieval Augmented Generation (RAG)
The embedding process also uses a language model. However, the language model used for embedding differs from the one used for generating answers (e.g., GPT). The embedding model is specialized in understanding context, while the generative language model excels at predicting the next word. Although both are language models, they serve different purposes, which means each question must be processed separately. Naturally, this requires two computations, leading to some inefficiency.
As a result, efforts are being made to integrate these two language models. This would lead to an all-in-one language model capable of both embedding for search and generating responses. In this newsletter, we’ll introduce GRIT, the first language model to integrate generation and embedding.
GRIT: Generative Representational Instruction Tuning
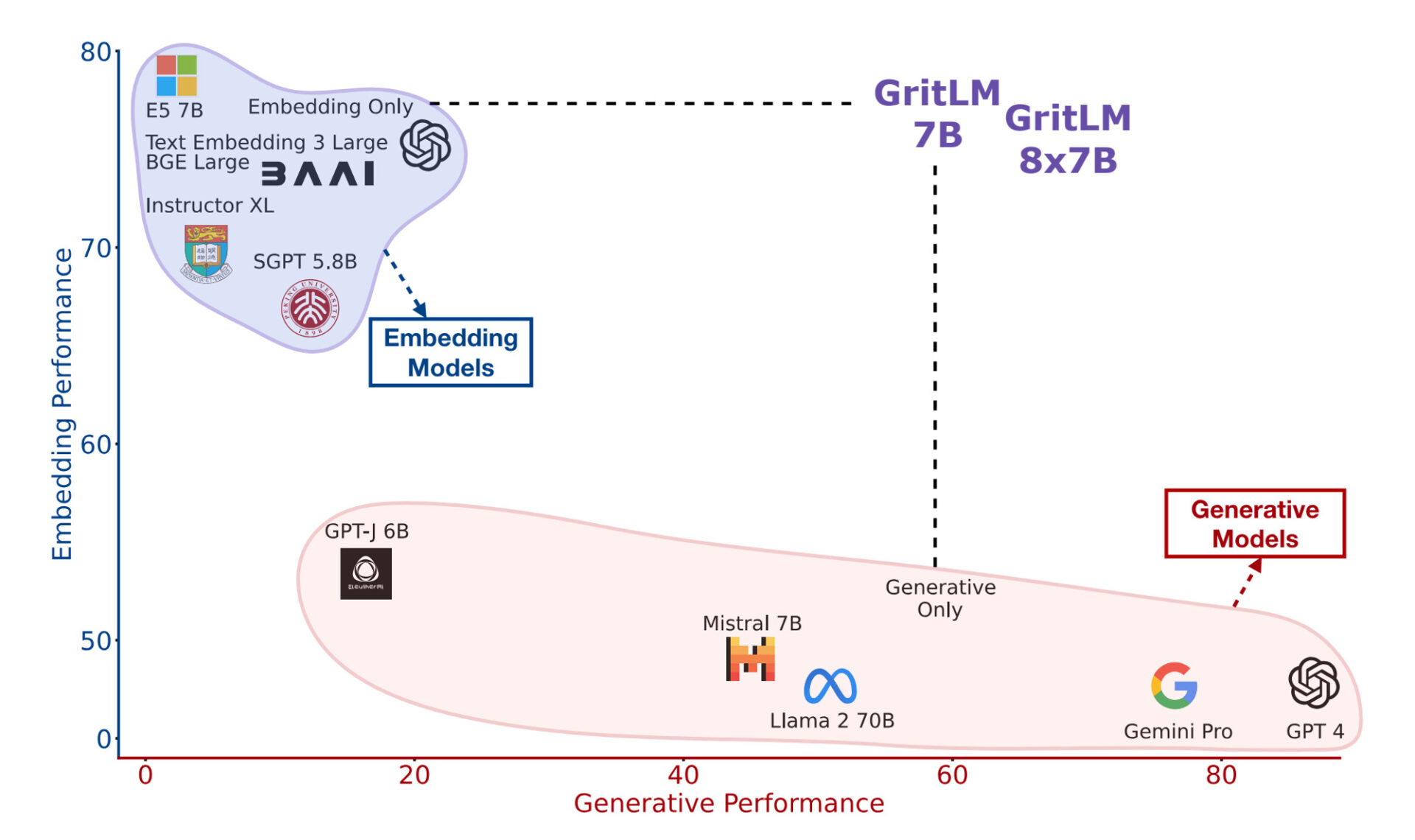
Source: Generative Representational Instruction Tuning (Muennighoff et al., 2024)
How did GRIT acquire both capabilities? GRIT applied Instruction Tuning for both embedding representation and generation within a single model.
For embedding, the goal is to obtain good vector values, while for generation, the aim is to predict the appropriate next token. Although the training process is the same, the final output differs, which requires slight adjustments in the model’s final stage.
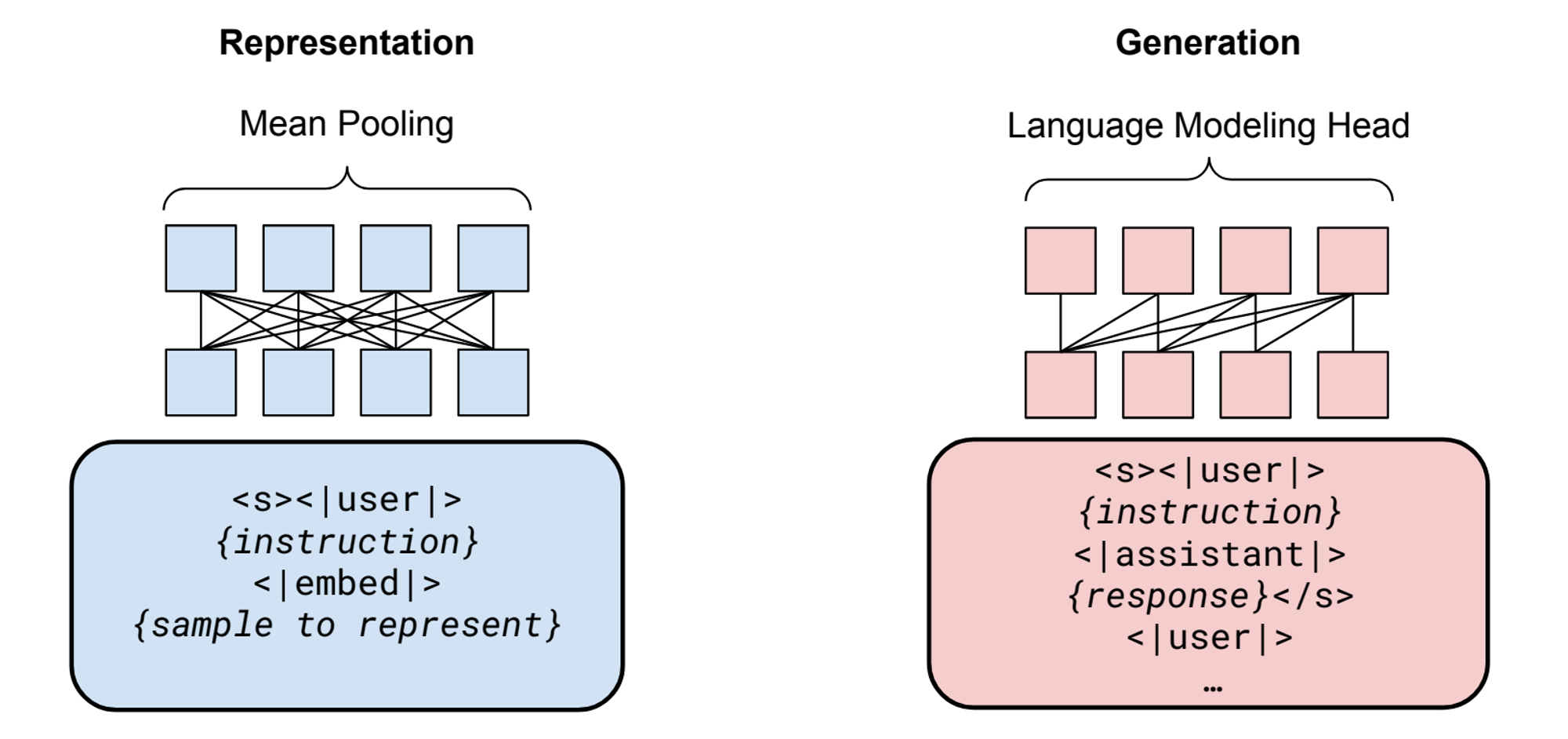
Source: Generative Representational Instruction Tuning (Muennighoff et al., 2024)
As illustrated above, in the embedding task, the weight values of the last hidden layer are averaged (Mean Pooling), while in the generation task, the last hidden layer is used to predict the next token. A special token is added to the instruction to determine which task to train on. The following diagram visualizes this process.
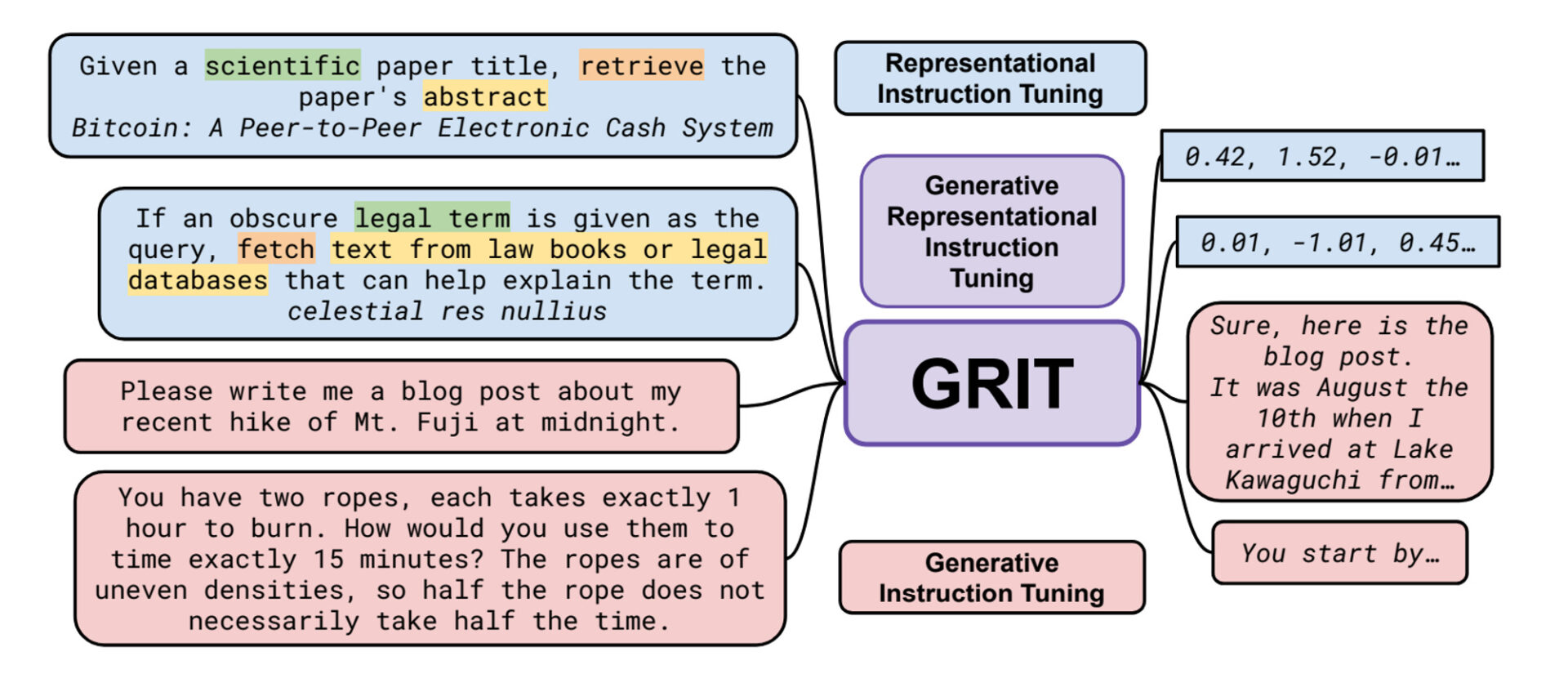
Source: Generative Representational Instruction Tuning (Muennighoff et al., 2024)
https://github.com/GritLMWhile the same form of instruction is input into the GRIT model, the output results differ. To achieve good embedding results, the training data for instruction tuning explicitly includes the domain, intent, and text unit. In the example above, the instruction specifies retrieving an abstract (unit) of a scientific paper (domain) with the intent to search (retrieve).
A base model is required for instruction tuning. The GRIT model is based on the Mistral 7B model, with additional instruction tuning applied. While it required more training to achieve both embedding and generation goals, the model ultimately achieved commendable performance in both areas (🔗 GritLM GitHub link).
Can it be applied to RAG?
In the traditional RAG method, the query was first input into the ’embedding model,’ and then the query, along with the retrieved results, was input again into the ‘generation model.’ However, by integrating these two functions into a single language model, inefficiencies were reduced. Information that has already been computed is cached, dramatically reducing retrieval speed.
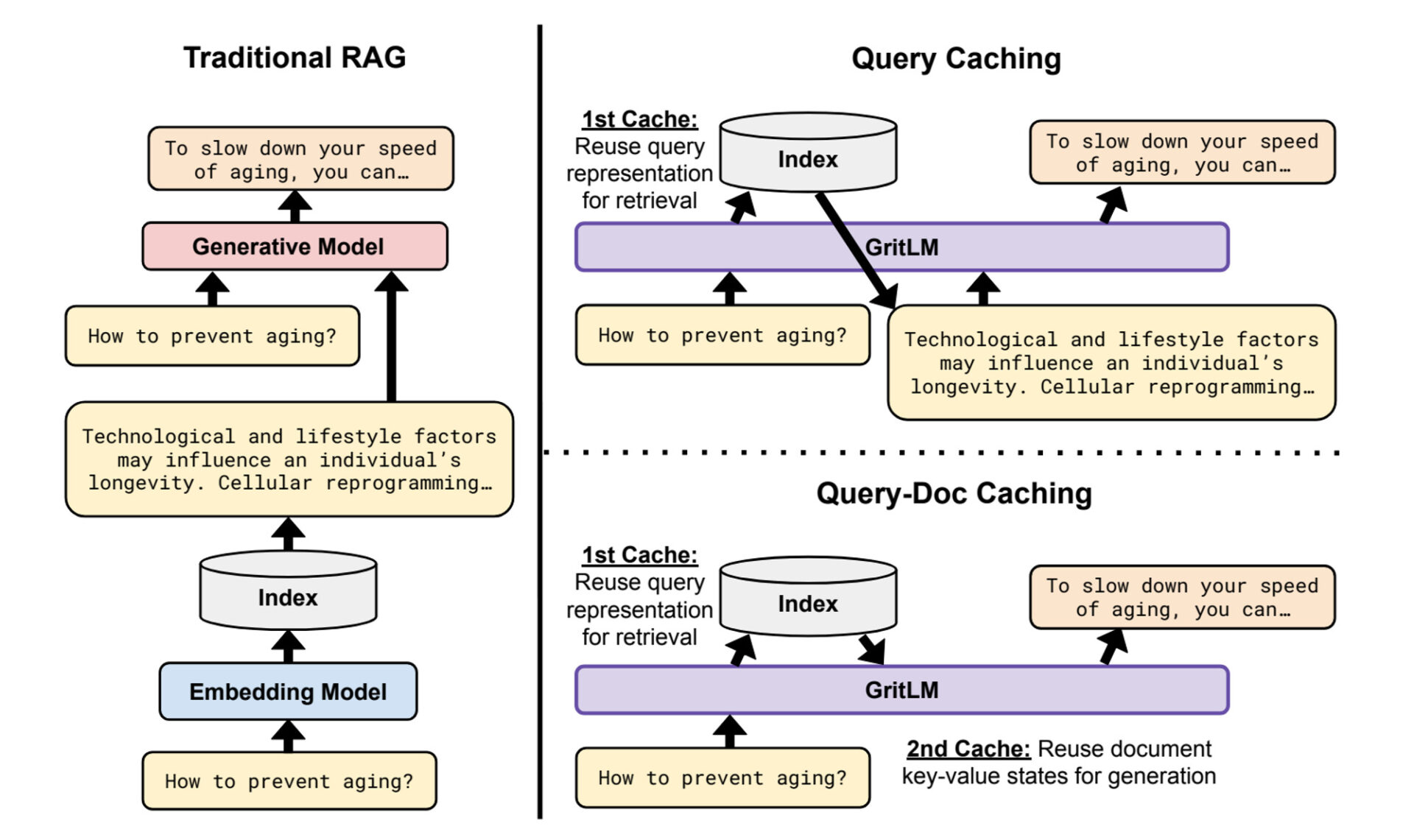
Source: Generative Representational Instruction Tuning (Muennighoff et al., 2024)
Let’s look at GRIT’s Query-Doc Caching method. The GRIT model (GritLM) first performs vector operations on the input question. This vector can be used for both document retrieval and as a condition for generation. Hence, it’s stored in the first cache (1st Cache) without needing to be computed twice. The same applies to the retrieved document; the document vector, also obtained through GritLM, can be used for generation. This information is stored in the second cache (2nd Cache). Utilizing both sets of information as input for GritLM, the desired answer is generated, which is the principle behind Query-Doc Caching.
However, its performance isn’t yet sufficient for practical RAG applications. Results from RAG are not significantly different from those obtained without RAG. The researchers attribute this to the GRIT model not being fine-tuned for this specific method.
While GRIT is based on Mistral 7B, the nature of its training structure allows for the implementation of this system on any model. This suggests a lot of potential for research on other models. There’s hope that applying this method to top-performing models like GPT-4 or Gemini Pro could allow for a more cost-effective implementation of RAG. Of course, further research is needed.


