
Earlier this year, OpenAI’s Sora showcased the potential of video generation models, sparking a wave of releases from other companies. On October 4th, Meta finally introduced its own text-to-video model, and impressively, it also includes the ability to generate audio. Let’s dive into Meta’s newly released foundational model, Movie Gen. 🍿
Meta's Generative Models
Movie Gen isn’t Meta’s first foray into image and video generation models. Meta has already introduced two foundational models. Let’s briefly review their features. The first is Make-A-Scene, announced in July 2022. As the name suggests, it allows users to generate desired images based on simple sketches and text. At that time, models like MidJourney and Stable Diffusion were gaining attention. Any new model had to outperform or distinguish itself from these. Meta’s Make-A-Scene stood out by incorporating not only text but also specific image conditions (sketches) into its generation process. This allowed creators to produce images or videos that were more aligned with their vision.

Make-A-Scene model that generates images based on sketches. Source: Meta AI Blog
There was another model that came before Movie Gen: Emu, announced in September 2023. Emu focused on the fact that existing image generation models often miss fine aesthetic details. To address this, Meta proposed a method based on Diffusion models, fine-tuned with a small number of images to capture intricate details. This process is often referred to as “Needles in a Haystack,” where Meta aimed to find fine image details like searching for needles in a haystack. After Emu, Meta introduced Emu-Edit, a model that allows for editing only specific parts of an image, emphasizing precise modifications.

Emu-Edit generates images that blend naturally with existing ones. Source: *Emu Edit: Precise Image Editing via Recognition and Generation Tasks* (Meta GenAI, 2023)
In both models, Meta emphasized the importance of “creative freedom” for creators. This means the model must allow creators to express their intentions in detail, generate results that align with their envisioned references, and enable precise editing for fine-tuning the output.
How is Movie Gen Different?

Source: Movie Gen: A Cast of Media Foundation Models (The Movie Gen team, 2024)
Unlike images, videos must maintain spatial and temporal consistency for objects and people. While individual frames may look natural, when put together, they can appear disjointed or unnatural. Sudden transitions or improper continuity between scenes can disrupt the flow. So, what technologies are integrated into the Movie Gen model to address these issues?
Technology Behind Movie Gen
Movie Gen Video is a foundation model with 30 billion parameters that combines Text-to-Image and Text-to-Video models to generate high-quality videos at 16 frames per second and up to 16 seconds in length. The model has “watched” around 1 billion images and 100 million video datasets, allowing it to naturally learn object movement, interaction, and physical relationships within a “visual world.” Through this training, Movie Gen Video can generate realistic videos while maintaining consistent quality across various resolutions and aspect ratios. To enhance this capability, the model undergoes Supervised Fine-Tuning (SFT), using high-quality video data and text captions.
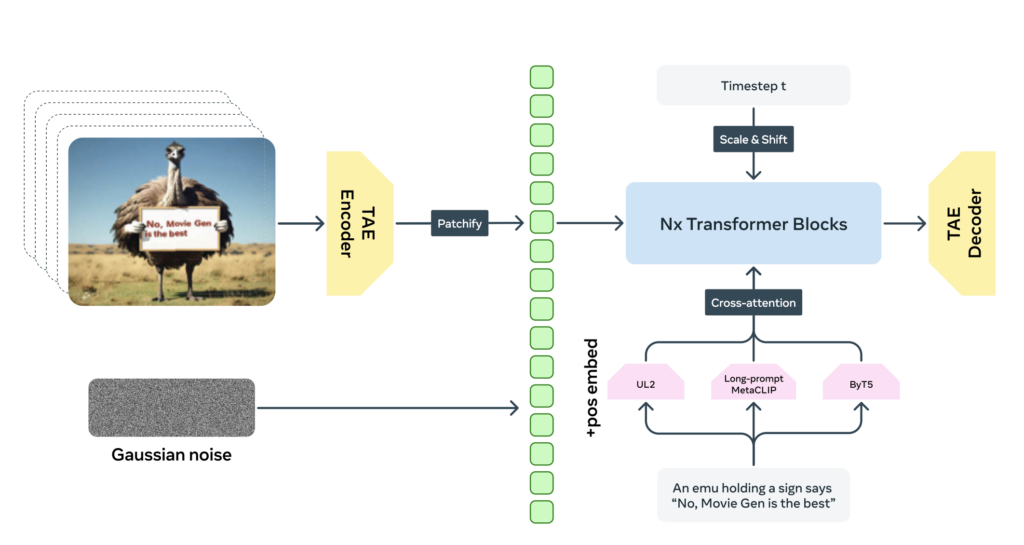
Movie Gen Video's architecture.


