
What is Embedding Tuning?
Embedding tuning plays a crucial role in optimizing RAG (Retrieval-Augmented Generation) by refining how questions and passages are embedded into numerical vectors. Standard RAG models often face matching issues between queries and answer chunks, especially when questions are short while passages are significantly longer.
Why Does This Issue Occur?
The length disparity between queries and passages leads to challenges in embedding space.
- Query: Typically short and concise, such as “What is this company’s revenue growth rate?”
- Passage: A longer, more detailed document excerpt, like a financial report segment.
Because queries are embedded as short vectors while passages are much more complex, their embeddings may not properly align, leading to inaccurate similarity scores and suboptimal retrieval results.
The Core of Embedding Tuning
Embedding tuning refers to adjusting the entire search pipeline—covering model selection, ranking mechanisms, and result ordering—to minimize mismatches between query and passage embeddings.
- Problem with default embedding models: Standard models transform both queries and passages into embeddings using the same approach, but due to their vastly different structures, this can lead to poor retrieval quality.
- The Role of Tuning: By optimizing embedding methods, we can ensure that queries and passages are mapped into a space where their similarity is more accurately captured, improving retrieval precision and overall RAG performance.

By adjusting the distribution differences between query embeddings and passage embeddings, embedding tuning ensures better matching between the two.
In the graph above, red dots (queries) and blue dots (documents) should be evenly mixed and positioned closely together to produce optimal search results. However, without proper tuning, the embeddings may be misaligned, leading to suboptimal retrieval.
Through the embedding tuning process, the distances between embedding vectors are refined through training, reducing distribution discrepancies. This allows the search engine to retrieve the most relevant passages for a given query with greater accuracy.
3. Performance Improvements After Tuning
The impact of embedding tuning can be observed through data distribution alignment and matching accuracy before and after tuning.
Before Tuning:
- Query embeddings and passage embeddings are not well-aligned, leading to lower retrieval reliability.
- Irrelevant passages may be selected as Top-k candidates, reducing answer accuracy.
After Tuning:
- Query embeddings are properly mapped to the passage embedding distribution, improving search relevance.
- Top-k retrieval quality improves, leading to higher response accuracy in RAG.
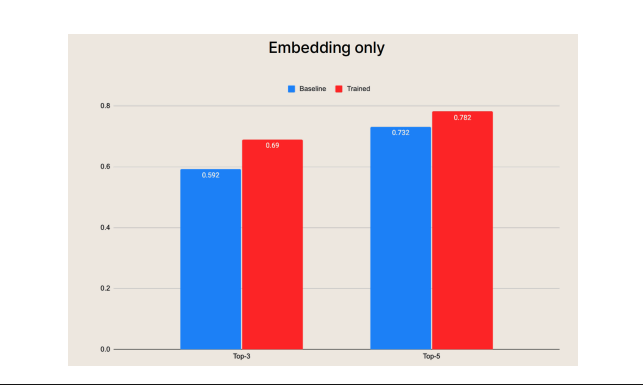
When comparing the baseline (blue) graph with the embedding-tuned trend (red) graph, we can confirm that embedding tuning pushes performance to the extreme, achieving up to a 10% improvement in retrieval accuracy.
Data Preparation and Training Impact for Embedding Tuning
To perform embedding tuning, we need question-context pairs, which consist of a query and an ideal passage as a response. For example, a query like “What is this company’s revenue growth rate?” would be paired with a response such as “According to the annual financial report of OO Corp, the revenue growth rate is…”
By training the search engine with this structured data, we can achieve the following improvements:
- Increased accuracy in similarity calculations between queries and passages.
- Higher probability of retrieving the most relevant passages for each query.
- Optimization of RAG’s upper-bound performance, maximizing the system’s retrieval efficiency.
Why Embedding Tuning is Essential for RAG
Embedding tuning is a critical step in pushing RAG performance to its limits. By structuring data effectively and fine-tuning search algorithms, we can achieve optimal query-passage matching, enabling AI-powered response systems to deliver more precise and reliable answers.


