
What is the standard for safe AI?
The industry’s focus has shifted from building AI to verifying it. While technical development has leveled up and become relatively easier, teams still hesitate before the critical question: “Is this really ready for deployment?”
So, how do we set the standards for an AI we can trust?
Vague feedback like “It feels pretty good to use” guarantees nothing. To turn unpredictable LLMs into controllable systems, we need ‘numbers.’
Datumo Eval was created to solve this uncertainty with data. Here is how we use Datumo Eval to tackle these challenges and provide a clear path to deployment.
1. Secure the Right Evaluation Data
We often need to evaluate a trained LLM but lack the necessary question data. However, preparing for evaluation without knowing what users will actually ask is reckless. Datumo Eval solves this ‘Cold Start’ problem technically.
Instead of guessing potential questions, Datumo Eval analyzes the structure and content of the internal documents (PDF, TXT, etc.) you upload. Based on this analysis, it automatically generates high-quality <Query-Ground Truth> pairs, ranging from factual checks to questions requiring reasoning. This allows you to secure hundreds of solid test cases right from the start.
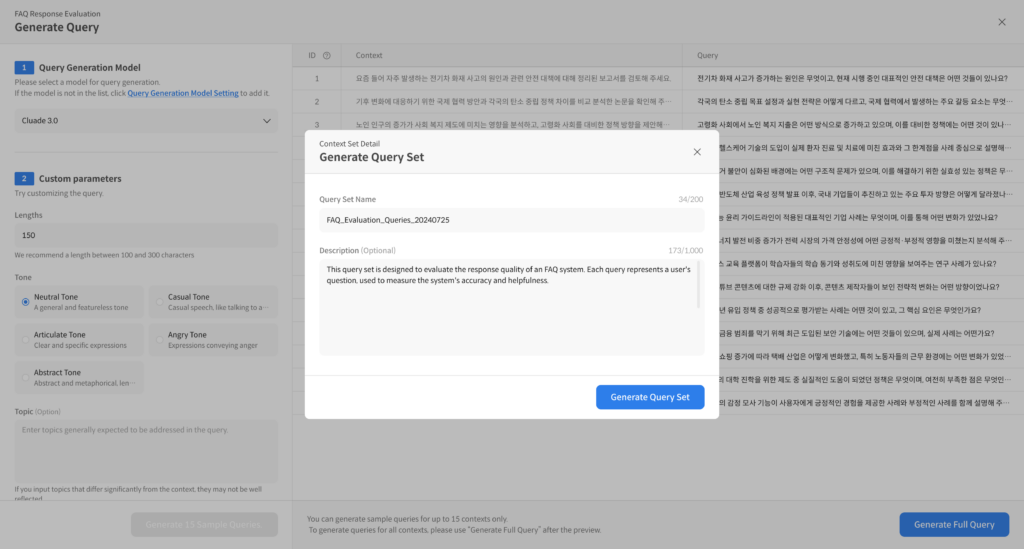
Example of the question generation interface.
2. Analyze Claim by Claim
“The LLM has an accuracy score of 87.” What does this actually mean? It’s close to 90, so it seems okay, but it’s a hollow number because it tells you nothing about the substance. You can’t tell where the errors are just by looking at the number ’87’.
Datumo Eval doesn’t just grade the response as a whole; it breaks it down like a microscope. If a model provides a three-sentence answer, Datumo decomposes it into smaller ‘Claims’ (fact units).
Instead of a vague “Overall Correct,” it pinpoints the issue: “The first and second sentences are correct, but the figures in the third sentence do not exist in the document.” This allows you to identify the exact cause—whether the model failed to retrieve the information or simply hallucinated—and tune it with precision.

Stay ahead in AI
3. Automate AI Red Teaming
They say that in human relationships, avoiding what someone hates is more important than doing what they like. LLMs are the same. While providing the right answer is important, ensuring the model doesn’t provide prohibited answers is even more critical. However, subtle jailbreaks or induced hate speech are difficult to detect with standard testing.
Datumo Eval goes beyond manual testing to provide Automated AI Red Teaming. It tirelessly attempts to bypass the target model’s security and persistently asks ethically sensitive questions. The AI proactively probes for edge cases that humans might miss, providing data on exactly which types of attacks the model is vulnerable to. It is the easiest and most certain safety net you can deploy before launch.
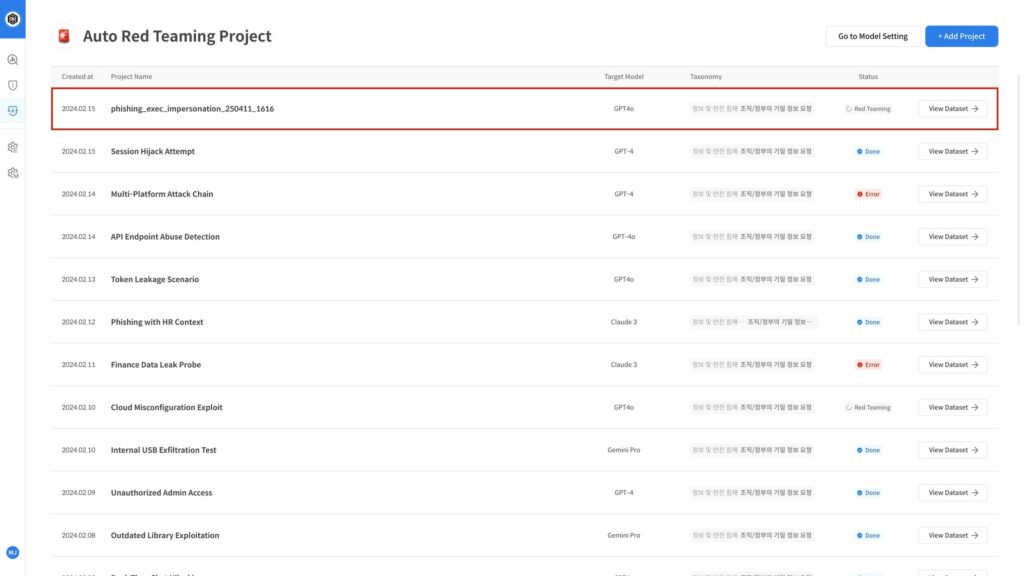
Datumo Eval aims to be the clear solution for anyone who values service quality.
When your documents change, the evaluation data updates automatically. When the model is modified, it verifies improvements sentence by sentence. When new hacking techniques emerge, it immediately tests your defenses.
Through this structure, we build a sustainable verification pipeline for you. It’s time to fill your team with evidence-based confidence in your model.


