
On August 27th, Google Research unveiled their study on the real-time game engine model, GameNGen. The model is powered by diffusion and reinforcement learning. Let’s take a closer look at the GameNGen model. 
What do we need?
Game developers create the rules and fun elements of a game, while users learn and play by those rules. This forms a repetitive loop that works as follows:
- Players control the game
- Game states get upgraded
- Results are displayed
Players interact with the game, causing changes and immediately seeing the results. When a player makes a request, the game engine updates the game state, fetching the appropriate images and elements to render the result on the screen. This process is something AI excels at.
How image generation models work
When you input a text prompt, the model generates high-quality images that match the prompt. Broadly speaking, this process is similar to game generation because both involve creating visuals based on user inputs.
GameNGen can replace traditional game engines by following this same principle. It generates the appropriate game state and outputs matching visuals based on the user’s input. GameNGen can produce 20 frames per second in real time.
How GameNGen Works

Poster of DOOM
GameNGen has completely replaced the game engine for DOOM, a classic FPS game. One of its defining features is its ability to run on almost any platform, from computers and consoles to unexpected devices like toasters, microwaves, and even treadmills.
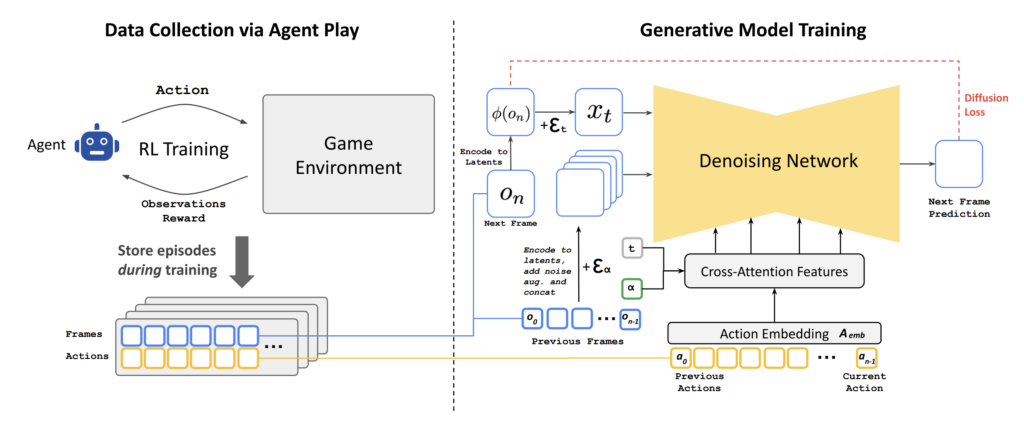
Model architecture of Google's GameNGen
GameNGen was developed through two major processes: first, training an agent to play the game to collect data, and second, training the model using the collected data.
To begin with, let’s explore how they trained the agent to collect data. In this context, a game simulates a world where players interact with its environment. The agent learns through this interaction, following principles similar to reinforcement learning. The researchers defined key components for agent training using the following symbols:
- Environment (E)
- State (S)
- Observation (O)
- Action (A)
- Rendering Logic (Value Function; V)
- Program Logic (Probability Function; p)
In DOOM, the researchers represented the dynamic memory as S, the screen’s rendered result as O, the process of rendering O based on S as V, the user’s input as A, and the resulting outcomes as p. Unlike traditional reinforcement learning, which aims to maximize rewards for optimal gameplay, this research focused on collecting a wide range of examples through human-like gameplay.
From Gameplay to Generative Model Training
The researchers trained the generative model, Stable Diffusion v1.4, by first collecting the agent’s actions and observations. Unlike text-based inputs, this model generates images based on prior actions and observations, creating a more dynamic and responsive system.
To address Auto-regressive Drift, a common issue during generative training, the researchers implemented Noise Augmentation. Auto-regressive Drift occurs when errors gradually accumulate over time due to differences between training and inference phases. Specifically, during training, the researchers used a process called Teacher-forcing, which requires the model to predict the next frame using real-world data. However, during inference, the model relies on its own outputs as input. If errors or noise are introduced, they can cascade, ultimately leading to a decline in quality over time.
To bridge this gap, Noise Augmentation deliberately adds Gaussian noise to context frames. By doing so, the model is exposed to unexpected scenarios, which enhances its resilience. As a result, it can maintain strong performance even in dynamic and unpredictable environments, much like real game conditions.

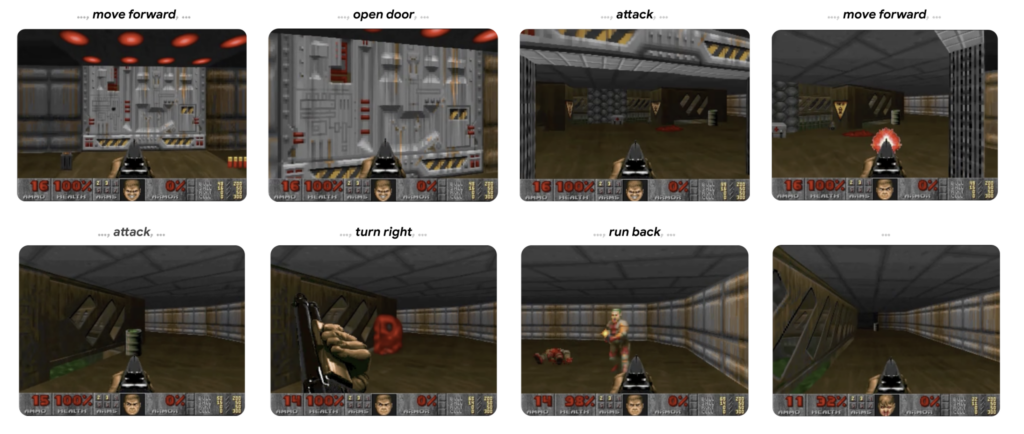
Comparison of GameNGen Model Predictions vs. Actual Results
GameNGen model is the result of such training, allowing humans to play the game directly. The predicted gameplay closely matched the actual gameplay, with human evaluators reporting that it was nearly indistinguishable from real DOOM gameplay footage when compared to GameNGen’s playthrough.
(For those curious about the actual gameplay footage, 🔗 check it out here!)
Of course, there are still many challenges to address. Currently, the model learns the game rules through reinforcement learning, but in the future, it will need to generate the rules and devise methods for training gameplay from the outset. Another issue is the excessive computational load compared to traditional game engines, especially in games that don’t require high graphical demands.
The significance of this research lies in showing the potential for replacing game engines with AI models. Notably, this model used Stable Diffusion v1.4, released in 2022, indicating endless possibilities for future improvements.


