
As advancements in AI continue, Large Language Models (LLMs) are playing increasingly critical roles across various industries. However, assessing their performance requires more complex and nuanced evaluation methods compared to traditional machine learning or deep learning models. Since LLMs are capable of generating diverse answers—especially in tasks like text generation—evaluation metrics must reflect this complexity. In this post, we’ll explore the key metrics used to evaluate LLMs, examine the challenges of ensuring AI reliability, and highlight the differences between LLM assessment and traditional model evaluations.
Key Metrics for Evaluating LLM Performance
Given the range of natural language processing (NLP) tasks LLMs are involved in, selecting the right metrics for performance evaluation is crucial. Here are some of the key metrics used:
- Accuracy: Measures how accurately the model responds to a given prompt.
- Diversity: Evaluates the variety and novelty of the generated text.
- Consistency: Assesses the model’s ability to provide coherent and contextually appropriate answers.
- Creativity: Measures the model’s capacity to generate original ideas or responses.
- Reasoning Ability: Evaluates the model’s logic and its ability to address complex problems.

Differences from Traditional Machine Learning and Deep Learning Metrics
Traditional models are often evaluated using metrics like precision, recall, F1 score, and AUC, which are useful when there are structured, correct answers. However, LLMs aim to generate unstructured text, where fixed answers do not exist. As a result, new metrics that consider diversity and creativity are introduced to assess LLM performance. Some common language model evaluation metrics include:
- BLEU (BiLingual Evaluation Understudy) Score: Measures how closely a generated sentence matches a reference sentence, typically used in machine translation.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation) Score: Used in summarization tasks to evaluate how much overlap exists between the generated text and the original text.
Challenges of AI Reliability and Ethical Considerations
As LLMs become more advanced, AI reliability is a growing concern. These models can sometimes provide biased or inaccurate information, raising significant challenges. It’s essential to address these concerns to ensure the reliability of AI systems. Common issues include:
- Bias: If the training data includes social biases, the model might generate biased or inaccurate responses.
- Information Trustworthiness: Ensuring that AI-generated information is accurate and reliable is crucial.
- Ethical Responsibility: Developers and users of AI systems must consider ethical implications, ensuring transparency and accountability in AI outputs.
Expanding LLM Evaluation Metrics
Beyond BLEU and ROUGE, LLM evaluation metrics continue to evolve. Some of the newer, more refined metrics include:
- METEOR (Metric for Evaluation of Translation with Explicit ORdering): A metric used in translation that takes into account stem matching and sentence structure, providing a more detailed assessment than BLEU.
- CIDEr (Consensus-based Image Description Evaluation): Commonly used in image description generation tasks, measuring similarity between the generated descriptions and multiple reference sentences.
- BERTScore: A semantic evaluation metric that compares the similarity between the generated text and reference text using pre-trained models like BERT.
These evolving metrics allow for more precise evaluations of LLM performance, enabling a deeper understanding of how well models function in various text-generation tasks.
DATUMO’s LLM Evaluation Solutions
We offer LLM evaluation solutions that maximize the performance of LLM-based services, applications, and products. Before deploying an LLM-based product, our solution provides a detailed analysis of the model’s performance using a variety of evaluation metrics and datasets, helping to optimize the model for specific business needs.
Our services include:
- High-Quality Question Generation: We generate large volumes of high-quality questions to efficiently and accurately evaluate LLM reliability.
- Comprehensive Performance Analysis: By evaluating the accuracy and reliability of LLM responses based on detailed criteria, we help improve model performance and guide future improvements.
- Real-Time Monitoring: We offer continuous performance monitoring of LLM models, allowing for quick identification and resolution of issues, ensuring optimal performance at all times.
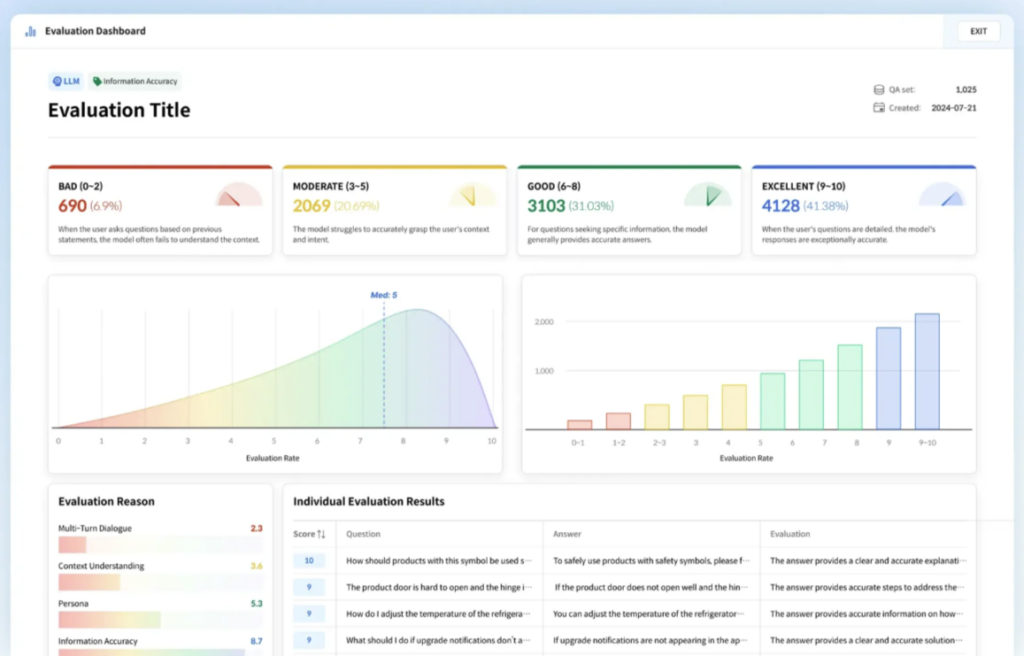
Screenshot from Datumo's LLM Evaluation Platform


