
A major announcement has sent ripples through the AI world—China’s AI startup DeepSeek has unveiled its LLM model, R1. What makes R1 stand out isn’t just its impressive performance but also its significantly lower development costs compared to competitors. On top of that, it has been released for free. Sensing the competitive shift, Sam Altman acknowledged R1 as an “impressive model, particularly around what they’re able to deliver for the price” while asserting that OpenAI is, of course, set to release “much better models.”
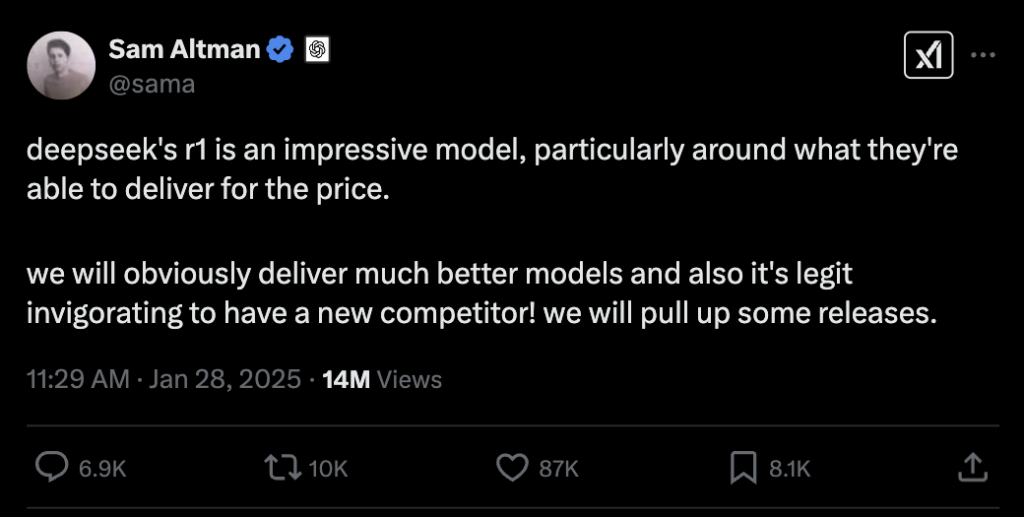
Shall we take a closer look at DeepSeek’s model—the one that seems to have sparked Sam Altman’s competitive fire? 🔎
DeepSeek: What's so special?
DeepSeek unveiled R1 as a model that not only competes with existing large-scale language models in terms of performance but also achieves this at a fraction of the cost. This release signifies more than just a technological breakthrough—it hints at a fundamental shift in how AI models are trained and optimized.
Cutting Costs While Boosting Performance
Unlike conventional models that require millions of dollars in training expenses, R1 was developed at a significantly lower cost. DeepSeek achieved this by pioneering an approach called automated reinforcement learning, minimizing human feedback while still delivering impressive results.
Traditional LLM training consists of two key phases: pretraining and post-training. DeepSeek’s innovation lies in the post-training phase, where they reduced human involvement, allowing the system to evaluate and refine itself autonomously.
Automated Reinforcement Learning: Instead of relying on humans to provide feedback, DeepSeek automated the reinforcement learning process. This method proved especially effective in tasks requiring logical reasoning, such as math and coding, while also drastically cutting costs.
A New Algorithm—Group Relative Policy Optimization (GRPO): DeepSeek introduced GRPO, a reinforcement learning algorithm designed to optimize model training efficiency. Unlike conventional reinforcement learning methods, which rely on separate prediction models, GRPO eliminates the need for additional models while enhancing LLM reasoning capabilities.

GRPO: A New Approach to Policy Optimization
- Core Concept:
Group Relative Policy Optimization (GRPO) redefines how reinforcement learning optimizes policies. Traditional reinforcement learning methods rely on a separate critic model to evaluate policy performance and guide training. In contrast, GRPO removes the need for a critic by comparing responses within a group and optimizing the policy based on their relative performance. Instead of relying on an external evaluation model, the system internally assesses and improves itself using peer comparisons. - Relation to PPO:
GRPO is a variation of Proximal Policy Optimization (PPO)—a widely used reinforcement learning algorithm. PPO utilizes clipping to prevent drastic policy updates, ensuring stable learning. While GRPO follows a similar principle, it eliminates the need for a critic model and instead uses intra-group comparisons to achieve more efficient optimization. - Reducing Computational Complexity:
One of GRPO’s key advantages is its ability to significantly lower computational complexity compared to traditional reinforcement learning methods. Standard approaches rely on value function estimators to evaluate the expected return of different actions, which adds computational overhead. GRPO bypasses this by leveraging relative performance rankings within a batch of generated responses, simplifying the training process while maintaining effectiveness. - Improved Learning Efficiency:
By optimizing based on relative performance within a group, GRPO allows LLMs to learn more efficiently. This is particularly crucial for LLMs, as they generate complex responses that require nuanced evaluation. Instead of an external evaluator determining the best responses, GRPO enables the model to refine itself dynamically based on internal comparisons, leading to more stable and effective training.
Is DeepSeek Coming to Get Us?
DeepSeek’s R1 model is making waves in the AI industry with its impressive price-to-performance ratio, reshaping the competitive landscape. Let’s take a quick look at their previous V3 model and the recently launched R1 model.
V3
The V3 model boasts performance comparable to OpenAI’s GPT-4 and was trained using the latest Nvidia H800 chips. Notably, DeepSeek managed to reduce the training costs for this large language model to under $6 million, making it a standout in terms of cost efficiency.
R1
The newly released R1 model excels in logical reasoning and mathematical problem-solving. Known for its cost-effectiveness, R1 is reportedly 20 to 50 times cheaper to run than OpenAI’s GPT-3. By automating reinforcement learning, DeepSeek has minimized human intervention in the training process while maintaining high performance.
However, there is a controversy surrounding content censorship. The R1 model reportedly restricts responses to sensitive topics such as Taiwan and Tiananmen Square, either refusing to answer or providing limited responses. This is due to legal requirements imposed by the Chinese government, which mandates strict content moderation for AI models operating in China. Interestingly, this censorship mechanism is only enforced when using DeepSeek’s official app, while the open-source version appears to have fewer restrictions, drawing the attention of global users.
Recently, the DeepSeek app surged to the top of Apple’s U.S. App Store, surpassing ChatGPT. Meanwhile, the Chinese government views DeepSeek’s success as a major milestone in its push for AI self-sufficiency. Just as the U.S. declared its ambitions in the AI race, China launched a swift counterattack. Rather than exploiting each other’s weaknesses, one can only hope for a spirit of fair competition—one that prioritizes not just technological supremacy but also the development of safe and responsible AI.


