
Last year, Datumo had three papers accepted at EMNLP 2025, one of the world’s top three NLP conferences!
Today, we’d like to take a closer look at one of them: COBA: Counterbias Text Augmentation for Mitigating Various Spurious Correlations via Semantic Triples. COBA is a study that leverages LLM-based text augmentation to reduce bias in training data while improving model performance, and it was selected as a main paper in the top 22% of submissions.
COBA goes beyond the “minimal change” limitation of traditional counterfactual data augmentation. By utilizing semantic triples and large language models, it introduces a framework that achieves both data diversity and robustness at the same time. Let’s dive in and explore how it works.

What COBA solves
Deep learning models tend to learn shortcuts by relying on spurious correlations that happen to exist in the training data, rather than focusing on true causal features. This often leads to poor generalization on out-of-distribution (OOD) data and is a major source of learned social biases.
To address this, prior work has explored Counterfactual Data Augmentation (CDA), which minimally modifies the original text while flipping the label. However, existing CDA approaches suffer from several limitations:
- Lack of diversity:
Because they are constrained to make minimal changes to the original text, the generated data often lacks syntactic diversity, which can lead to overfitting. - Dependence on a single model:
Most prior methods rely on a single model to identify important words. However, the analysis in this paper shows that what a model considers “important” varies significantly depending on the architecture (e.g., BERT vs. RoBERTa).
To overcome these challenges, COBA introduces the concept of “counter-bias” and proposes a unified framework that generates robust and diverse augmented data through the decomposition and recomposition of semantic triples.
Why single model is not sufficient
One of the key limitations identified earlier is dependence on a single model. To better understand this issue, let’s take a look at the researchers’ analysis of word importance.
The study examined four pretrained language models (PLMs)—BERT-base, BERT-large, RoBERTa-large, and DistilBERT—and extracted the top five important words for each using methods such as LIME and Integrated Gradients (IG). Here, “important words” do not simply refer to high-frequency terms, but to features that the model considers decisive when making a prediction. Using LIME* and Integrated Gradients, the researchers traced back which specific words in a sentence led each model to decide, for example, “this is positive” or “this is negative.”
*LIME: an algorithm that explains a black-box model’s predictions by identifying which words it considered most important for a given decision.
Inconsistency in important words across models
So how often did all four models unanimously agree that “this word is important”?

Ratio of duplication among the top 5 important words across models. Source: Datumo.
Looking at the table above, even on the SST-2 dataset, which consists of relatively short sentences, the four models agree on important words only 26.72% of the time. For the IMDB dataset, where sentences are longer and more complex, this ratio drops sharply to just 8.64%. This suggests that augmenting data based on the importance judgments of a single model can result in data that is overfitted to that model’s specific biases.
Differences in part-of-speech (POS) dependence across models
The distribution of parts of speech among important words also varied by model. Intuitively, for a sentiment analysis task, adjectives or adverbs such as “boring” or “interesting” should play a central role. But how did the models actually behave?
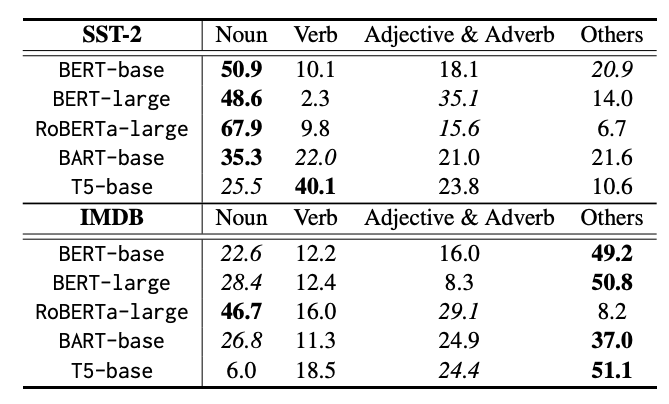
Part-of-speech (POS) distribution of the top 5 important words by model and dataset. Source: Datumo.
From the table above, we can see that BERT-based models rely excessively on nouns. Overdependence on nouns increases the risk of learning spurious correlations, such as making predictions based on person names or proper nouns that are unrelated to sentiment.
In contrast, the T5 model appears to place the greatest importance on verbs. These differences highlight that each model “views” the data differently. For this reason, COBA adopts an ensemble-based approach rather than relying on a single model, enabling it to identify more universal spurious words and truly principal words.

Stay ahead in AI
Understanding the COBA Framework
Building on the analyses we just discussed, COBA proposes a three-stage pipeline that decomposes text into semantic units and manipulates them in a controlled and systematic way.

The full COBA framework pipeline, illustrating how original data is transformed into counter-bias data. Source: Datumo.
Semantic Triple Decomposition
Using an LLM, complex sentences are structured into semantic triples in the form of [Subject, Predicate, Object]. This step extracts the core semantic backbone of a sentence.
Triple-level Manipulation
Triples that contain spurious words are kept unchanged (Maintain Spurious Words). By showing the model that the label can change even when biased elements remain, COBA encourages the model to unlearn spurious correlations.
Triples containing principal words identified by the ensemble are modified to flip the label (Modifying Principal Words).
Additional diversity is introduced through gender-related word substitutions and triple permutation.
Data Reconstruction
The manipulated triples are fed back into an LLM to be reconstructed into natural, fluent sentences. Thanks to the wide range of linguistic variations generated in this step, the resulting data becomes more robust to out-of-distribution (OOD) scenarios.
Results
The effectiveness of COBA is clearly reflected in quantitative results. Across major benchmarks such as SST-2, IMDB, and SNLI, COBA outperforms recent state-of-the-art augmentation methods, including AutoCAD and AugGPT.
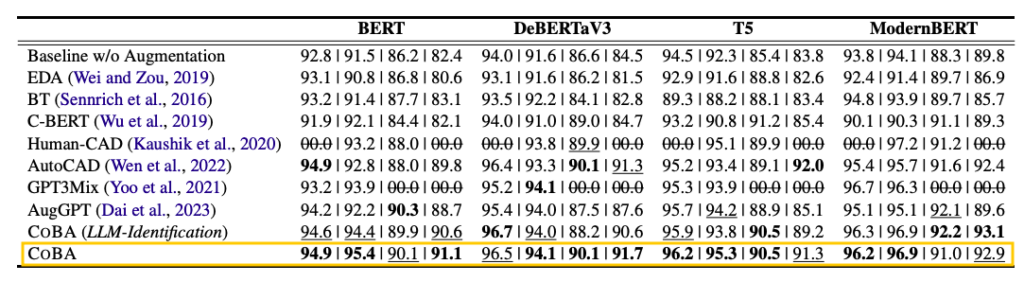
Comparison of downstream task performance across different data augmentation strategies. Source: Datumo.
An especially interesting comparison is with COBA (LLM-Identification). The researchers also ran experiments where bias identification was handled entirely by an LLM, but the original COBA—based on an ensemble of multiple models—achieved better performance. This suggests that capturing biases actually experienced by real models through an ensemble is more effective at mitigating spurious correlations than relying solely on an LLM’s general knowledge.
COBA also achieved a high score of 87.2 on the Human-CAD test set, which consists of manually annotated counterfactual examples. This demonstrates COBA’s robustness against traps intentionally designed by humans. In addition, it produces highly natural text. Let’s take a look at some real generated examples below.
Qualitative comparison between Human-CAD and COBA augmented data. Source: Datumo.
Human-edited Human-CAD examples often retain the original word order and simply replace specific words. In contrast, COBA flexibly reorganizes sentence structure without breaking the context and precisely modifies only the core sentiment expressions. As a result, it is able to generate much richer and more natural counter-bias data.
Kyohoon Jin, the first author of the paper and a researcher at Datumo, explained that the goal was to develop “a data augmentation method that enhances fairness and diversity by automatically enriching limited expressions using LLMs.” Rather than simply increasing the amount of data, COBA adopts a counter-bias strategy that teaches models, through the data itself, what they should learn and what they should ignore, ultimately aiming to build more trustworthy AI systems.
From data you can trust to AI you can deploy with confidence, Datumo supports the entire journey. Through continuous research, Datumo remains committed to delivering best-in-class AI reliability evaluation solutions.


