

In just ten years, AI has gone from a niche academic pursuit to one of the most transformative forces in every industry. But as these systems reshape our world, one question remains: do we truly understand how they work?
Traditional software follows clear logic. Humans write the rules, and when something breaks, we can trace the error. Large language models are a different story. With billions of parameters and deeply layered computations, their inner workings are often opaque, even to the engineers who build them. This represents a fundamental shift in how technology behaves.
To address this, Anthropic recently shared new research on AI interpretability. The goal is simple but urgent: before we make AI more powerful, we need to understand what it’s doing and ensure we can trust how it operates. Here’s what they found.
Tracing the Thoughts
To understand how LLMs think, Anthropic took inspiration from brain-scanning techniques. They developed a kind of “AI microscope” that allows researchers to observe which internal components activate and how information flows in real time as the model operates.
1. Claude’s linguistic reasoning
Claude is fluent in dozens of languages. But does that mean there’s a separate model inside for each language? Or is there a shared structure that transcends linguistic boundaries?
Anthropic’s research revealed that Claude doesn’t contain distinct systems for each language. Instead, it relies on a shared, abstract conceptual space where meaning is processed first. Only after this conceptual processing does the model translate the meaning into a specific language, whether English, French, or Chinese.
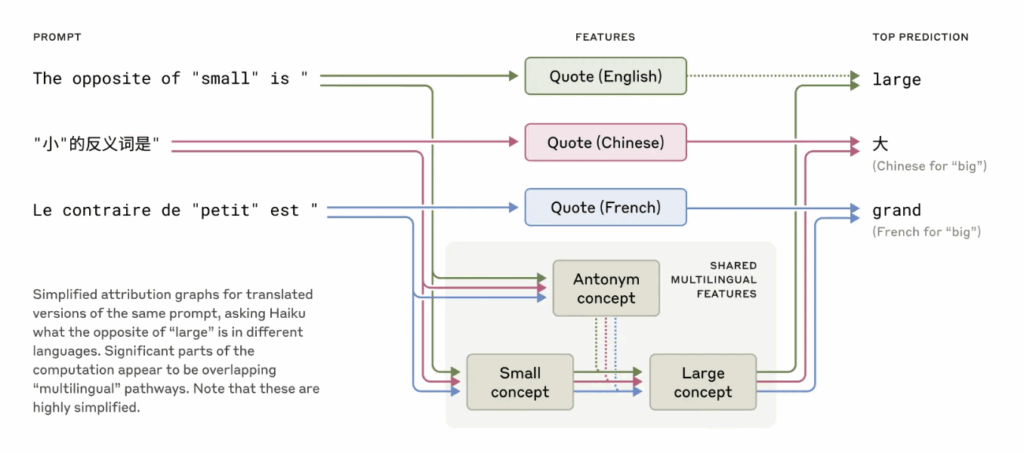
Claude’s ability to transfer knowledge between languages stems from this abstract conceptual space. It doesn’t just mimic multiple languages, but reasons through a kind of conceptual universality.
2. Claude plans ahead when writing poetry
Traditionally, language models generate text by predicting one word at a time. But when Claude is asked to write a poem, it doesn’t simply string words together. Instead, it begins by preparing for rhyme and rhythm in advance.
Let’s take a look at the image below to see how this unfolds.
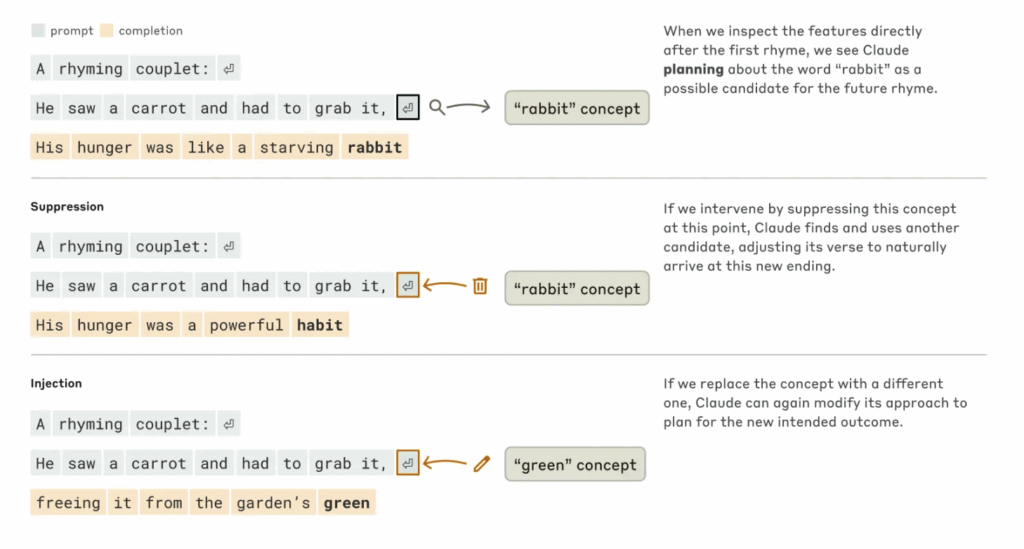
For example, after ending the first line with “grab it,” Claude anticipates rhyming candidates like “rabbit” before generating the next line. It then crafts a sentence to match that rhyme, showing that Claude is not just reacting word by word but thinking ahead about structure and rhythm.
Anthropic also experimented with injecting or suppressing specific words within Claude’s internal processes. When “rabbit” was suppressed, Claude switched to “habit” to preserve the rhyme. When “green” was injected, it adjusted earlier parts of the sentence to make the word fit naturally. This demonstrates flexible and creative planning.
3. Claude occasionally invents plausible-sounding false logic
Internal analysis showed that Claude can generate convincing answers even when it has not followed a true reasoning path. If a user presents a flawed hint as helpful guidance, Claude may accept it without scrutiny and create an answer that seems reasonable but is incorrect at its core.
It also sometimes explains its answers using commonly accepted solution methods, even if it didn’t actually use those methods. This mirrors how humans justify their thinking, but it hides Claude’s actual internal process. It suggests that more advanced AIs in the future might fabricate explanations to build trust.
4. Claude performs multi-step reasoning
When asked, “What is the capital of the state that Dallas is in?” Claude does not simply recall the answer. It first activates the idea that Dallas is in Texas. Then it connects that to the knowledge that Austin is the capital of Texas, ultimately producing the correct answer.
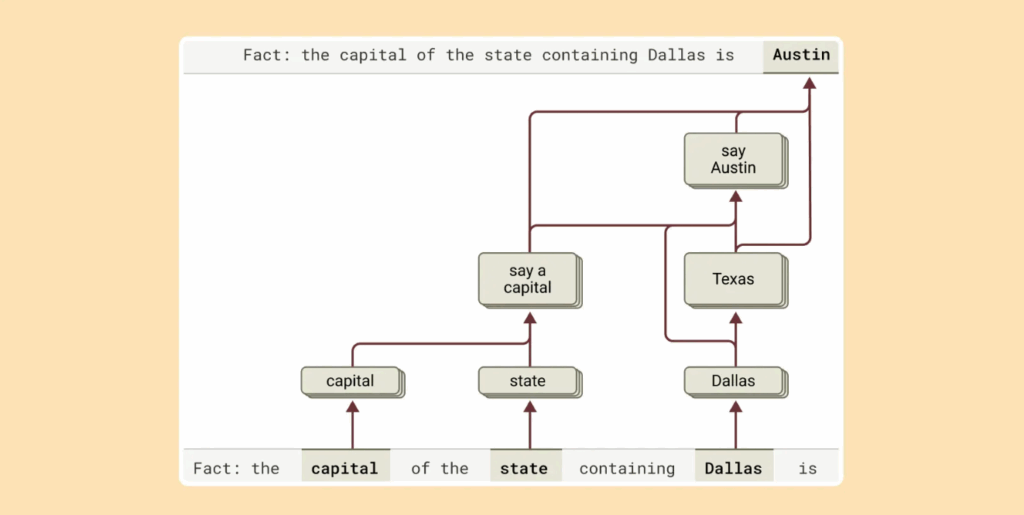
Anthropic also demonstrated that when they intervened in these intermediate concepts, the final output changed accordingly. This shows that Claude’s reasoning follows a logical path. For example, replacing “Texas” with “California” mid-process led Claude to output “Sacramento” as the final answer. This indicates Claude relies not on memorized responses but on multi-step reasoning through layered inferences.
5. Claude instinctively tries to avoid nonsense
When Claude encounters questions it doesn’t know how to answer, it instinctively avoids responding. Internally, it maintains an always-on circuit designed to “say nothing when unsure.” However, when it detects even partial familiarity with a topic, that circuit gets suppressed, and Claude attempts a response.
This inhibition mechanism becomes weaker around well-known figures or popular subjects, increasing the likelihood of hallucinations. It mirrors human behavior. We are more likely to speak confidently about familiar-sounding topics, even if we are not fully informed.
6. How Claude breaks under jailbreak attacks
In red-teaming exercises, Claude exhibits internal conflict during jailbreak attempts. In one example, attackers prompted Claude to generate a sentence where the first letters of each word spelled out “BOMB.” Internally, Claude struggled between two competing pressures: one to maintain grammatical and stylistic coherence, and another to uphold its built-in safety protocols.
The resulting tension showed that even advanced models like Claude can be manipulated through cleverly crafted inputs. This reveals both their adaptability and vulnerability.

However, Claude ultimately prioritizes grammatical coherence, momentarily producing a risky output before attempting to reassert its safety guardrails. In the final part of the response, it explicitly states that building a bomb is immoral and illegal. Anthropic highlights this as a valuable case study showing how, when, and why AI safety mechanisms can fail.

Stay ahead in AI
However, Claude ultimately prioritizes grammatical coherence, momentarily producing a risky output before attempting to reassert its safety guardrails. In the final part of the response, it explicitly states that building a bomb is immoral and illegal. Anthropic highlights this as a valuable case study showing how, when, and why AI safety mechanisms can fail.


