
In June 2025, the U.S. District Court for the Northern District of California issued a landmark ruling on a case involving generative AI startup Anthropic, which used millions of books to train its AI models. (Link to ruling)
The key points of the ruling are:
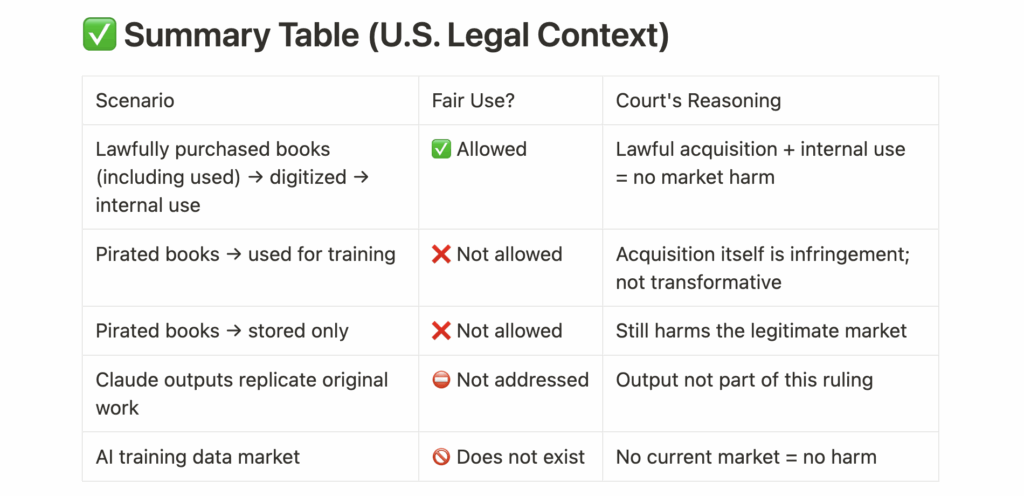
✅ Using legally purchased books for AI training is fair use
❌ Using illegally downloaded books for storage or training is copyright infringement
The court firmly ruled that training AI on lawfully acquired books qualifies as fair use, consistent with precedents like Google Books and HathiTrust. This part of the decision is unlikely to be overturned on appeal.
Still, as the AI training data market matures, there’s a real chance this could change.
The ruling sets an important baseline for how AI companies can use data and serves as a key precedent for copyright holders, tech firms, and policymakers.
1. AI can be trained on legally bought books
Anthropic purchased millions of books from used bookstores and distributors, then unbound and scanned them using specialized equipment to build an internal digital library. These books were used to train AI models such as Claude.
The court ruled this to be clear fair use:
“Anthropic purchased its print copies fair and square… It did not create new copies to share or sell outside.”
“This use was even more clearly transformative than those in Texaco, Google, and Sony Betamax.”
— Decision, p.15–16
In other words, converting legally purchased physical books into digital format for internal research does not harm the market for the original work, and the purpose of AI training is considered “spectacularly transformative.”
2. Pirated books: use and storage banned
Anthropic also downloaded approximately 7 million books from piracy sources like LibGen, Books3, and PiLiMi. Some were used for training Claude; others were stored for potential future use.
The court explicitly deemed this acquisition to be copyright infringement:
“Pirating copies to build a research library… was its own use — and not a transformative one.”
“Piracy was the point: To build a central library… but without paying for it.”
— Decision, p.18, p.21
Thus, even storing illegally obtained books, regardless of actual use, was considered a market-substituting act and a violation of copyright.
3. A central library isn't a problem by itself
Some media summaries suggested that “creating a central digital library” exceeds the scope of fair use. However, this interpretation applies only to infringing books.
The court acknowledged that digitizing lawfully purchased books for internal search and browsing qualifies as fair use:
“Anthropic’s format-change from print library copies to digital library copies was transformative under fair use factor one.”
— Decision, p.18
The problem was building a central dataset using pirated books, not the internal library of lawfully acquired ones.

Stay ahead in AI
4. Core factor: market effect
Among the four factors used to evaluate fair use, the most critical is whether the usage impacts the actual market for the original work. The court clarified:
“Fair use analysis considers the effect on actual markets, not hypothetical ones.”
And it further noted that:
“The AI training data market is not presently established… so the use does not affect the potential market.”
Therefore, the court concluded that there was no market harm to copyright holders under current conditions and ruled in favor of fair use.
TLDR; Permitted for now, but may change
Key takeaways from this ruling include:
1. Why can something still be fair use even if the author objects?
What does “fair use” really mean?
Fair use is a legal exception that allows certain uses without the copyright holder’s permission. The court emphasized the following:
- AI training does not replace the existing market for the book
- The outputs do not reproduce or copy the original work
- There is currently no AI training data market
Thus, the court found no harm to the copyright holder’s economic interests- at least for now.
📌 But if a market for AI training licenses does emerge, the “market substitution” argument could flip the fair use ruling.
2. Why was a lawsuit needed if pirated books are obviously illegal?
A warning against the myth of “research makes it okay”
Many academic institutions assume “research purposes” justify unlicensed use. This ruling clearly rejected that defense. Anthropic could have lawfully purchased the books but opted for piracy to avoid legal and logistical hassles.
The court saw this as deliberate evasion, ruling it to be infringement regardless of how transformative the use might be.
📌 In short:
No matter how noble the purpose, if the source is illegal, it’s not fair use.
This reaffirms the ethical and legal risks of assuming “research = fair use.”
🌟 You can already access lawful AI training data
If your AI project needs large-scale text, audio, or image datasets, the Datumo Dataset Store provides:
✅ Legally licensed training data through direct agreement with copyright holders
✅ High-quality datasets that are safe for commercial use
✅ Domain-specific data tailored for various industries
📌 Instead of relying on the uncertainty of fair use,
a verified data platform offers the most practical and risk-free option at this time.
🛒 Check out what we have: Dataset Store


