
As AI technology—particularly large language models (LLMs)—continues to advance rapidly, concerns about the safety and reliability of these systems are growing. AI Red Teaming has emerged as an effective solution for identifying and mitigating potential risks in LLMs. By systematically exploring and reinforcing LLM vulnerabilities, AI Red Teaming plays a crucial role in promoting the safe development and use of AI technology.
The Definition and Importance of LLM Red Teaming
LLM Red Teaming is an approach that uses deliberately adversarial prompts to test and evaluate LLMs, aiming to uncover inappropriate or harmful vulnerabilities within the model. This approach encourages LLMs to produce improper or risky responses and seeks to address the following goals:
- Preventing hallucination and misinformation
- Detecting harmful content (such as violence, hate speech, and false information)
- Identifying biases and discriminatory stereotypes
- Preventing data leakage
- Assessing inconsistent responses
- Blocking undesirable output formats
AI Red Teaming Challenge in Korea
In April 2024, Datumo organized Korea’s first and largest AI Red Teaming Challenge. This major event, which gathered around 1,000 participants, spanned two days of intensive programming. Leading AI companies, including SK Telecom, Naver, 42Maru, and Upstage, took part, testing various LLM attack methods. This challenge was a significant step in raising awareness of AI safety in Korea and strengthening collaboration between academia and industry.
Red Teaming Methodology
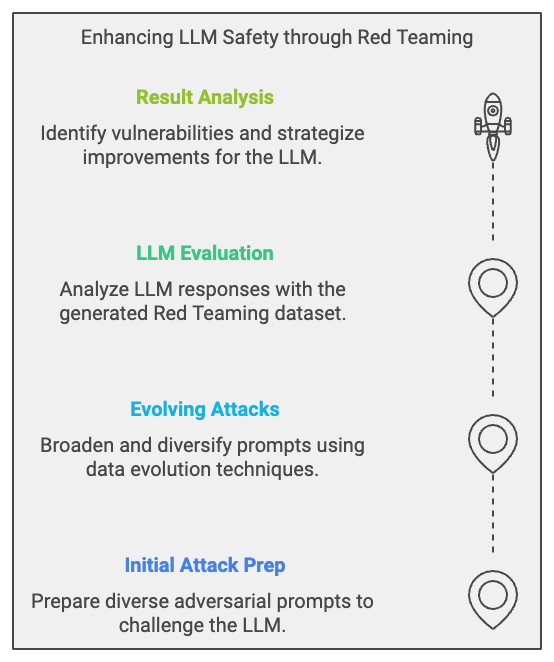
Effective LLM Red Teaming includes the following stages:
- Initial Adversarial Attack Preparation: Assemble an initial Red Teaming prompt set using various attack techniques:
- Direct Prompt Injection
- Prompt Probing
- Gray-box Prompt Attacks
- Jailbreaking
- Evolution of Adversarial Attacks: Use data evolution techniques to expand and diversify the initial prompt set.
- LLM Evaluation: Assess the LLM’s responses using the generated Red Teaming dataset.
- Result Analysis and Improvement: Identify the LLM’s vulnerabilities based on the evaluation results and develop strategies for improvement.
Red Teaming Tools and Frameworks
To enhance the effectiveness of LLM Red Teaming, open-source frameworks like DeepEval can be utilized. These tools enable structured, systematic assessments by automating many aspects of the Red Teaming process, which involves rigorously testing models to identify vulnerabilities and evaluate safety measures.
DeepEval, for instance, supports large-scale testing by allowing researchers to conduct diverse evaluations across various prompts and scenarios. Such tools help identify potential weaknesses in LLMs, including susceptibility to harmful content generation, biases, and accuracy errors, which are critical for ensuring these models meet safety and ethical standards before deployment.
By streamlining the testing process, these frameworks facilitate efficient, comprehensive assessments, making them valuable assets in the development and deployment of more reliable LLMs.
Conclusion
AI Red Teaming, particularly for large language models (LLMs), is essential to bolstering the safety and reliability of AI systems. The recent large-scale Red Teaming Challenge in Korea stands out as a pioneering effort in this domain, showcasing the power of rigorous testing to enhance model robustness and trustworthiness.
As AI technology grows increasingly complex and embedded in our everyday lives, the role of Red Teaming will only become more vital. By identifying vulnerabilities and stress-testing systems under diverse scenarios, AI Red Teaming helps to safeguard against potential risksbefore they reach users.


