
AI’s ability to understand images and describe them in natural language is improving rapidly. Yet, unlike humans, these models still struggle to interpret context and apply what they have seen before to new situations.
A paper presented at ICCV 2025, “Teaching VLMs to Localize Specific Objects from In-Context Examples,” takes on this challenge. The researchers propose a new method for training large Vision-Language Models (VLMs) to perform context-based, personalized object localization—essentially teaching the model to recognize specific objects, like your own cat, based on just a few contextual examples.
So, what did they discover?
The Idea
This experiment begins with a simple question:
After seeing just a few photos of my cat, Snoofkin,
can a Vision-Language Model recognize Snoofkin in other images as well?
Current VLMs excel at identifying broad categories like “cat” or “airplane,” but they struggle when it comes to recognizing a specific cat or an object whose meaning changes depending on context. The researchers proposed a method called few-shot personalized localization, which trains the model to locate a particular object in new scenes using only a small number of examples.

An example of object detection using IPLoc. Source: the paper.
In the figure above, the In-context Image shows the object that needs to be identified, while the Query Image is the photo in which the model must detect that object. The model’s task is to find the same type of object it saw in the example image within the query image. With the researchers’ proposed method applied, Our Model seems to have successfully located the correct object, doesn’t it?
The Experiment
Believing that “to teach AI context, you must provide data that contains context,” the researchers did not design a new model architecture but instead developed a new training strategy. Their goal was to enhance a model’s contextual understanding through data itself. Using a data-centric approach, they introduced a method called IPLoc (In-context Personalized Localization), which enables existing VLMs to interpret context more effectively. Let’s take a look at how their experiments were designed.
1. Video Object Tracking Data
To help the model experience tracking the same object across different scenes, the researchers used three large-scale video tracking datasets:
TAO (Tracking Any Object): 839 categories, complex multi-object tracking dataset
LaSOT: Long-term tracking of a single object (average of 2,500 frames per video)
GOT-10k: 10,000 real-world object sequences
These datasets contain identical objects appearing under different lighting conditions, angles, and backgrounds. This allows the model not only to learn what an object is, but also how to recognize the same object under varying conditions. Instead of memorizing categories, the model learns context-based generalization.
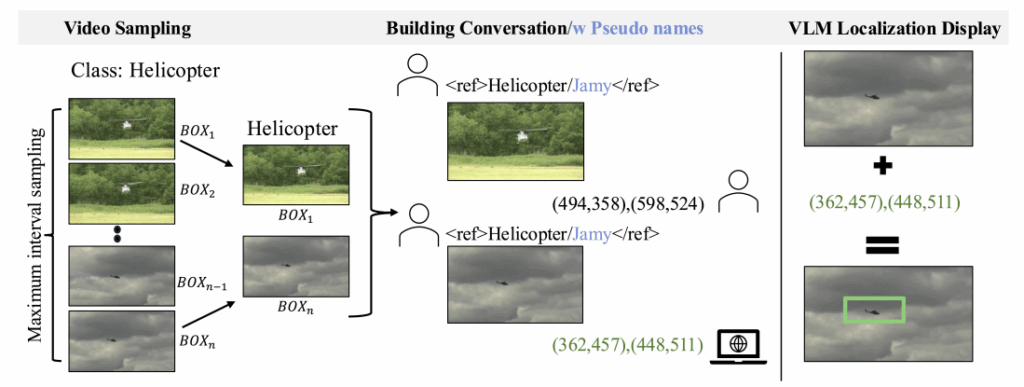
2. Conversational Training Format
A unique feature of IPLoc is that it reformats data into a conversational format. Let’s see an example.

The structure above illustrates how the model sequentially receives multiple in-context examples and then predicts the location of the same object when prompted with a final “Prediction” request.
The user provides n example images along with the corresponding object coordinates, followed by a final instruction: “Find the same object in this image.” The model (acting as the Assistant) uses all previously given information as context and outputs the predicted bounding box coordinates.
In essence, the model treats the earlier examples as a kind of conversational context, reasoning over them to infer the location of the same object in the final image.

Stay ahead in AI
3. Fake Name Regularization
Here comes a clever twist. To prevent the model from relying on prior knowledge of object names, the researchers replaced real object names with meaningless fake ones.
For example, if the word “cat” is replaced with “Snoofkin,” the model can no longer depend on its learned concept of a cat. Instead, it must rely solely on visual similarity to make its prediction. This technique encourages the model to learn based on contextual resemblance rather than linguistic definitions.
AI red teaming strategies. Source: Google
4. Fine-tuning
For efficient training, the researchers also applied LoRA (Low-Rank Adaptation). LoRA allows a model to acquire new capabilities by adjusting only a small subset of its parameters instead of retraining the entire network.
This approach enables the model to retain its existing linguistic and visual understanding while gaining the additional ability to perform personalized, context-aware learning.
The Results
The researchers applied IPLoc to the Qwen2-VL model and then compared its performance with existing models such as GPT-4o, LLaVA, and Idefics.
For evaluation, they used three benchmark datasets: PDM, PerSeg, and ICL-LaSOT.
Let’s take a look at the results.
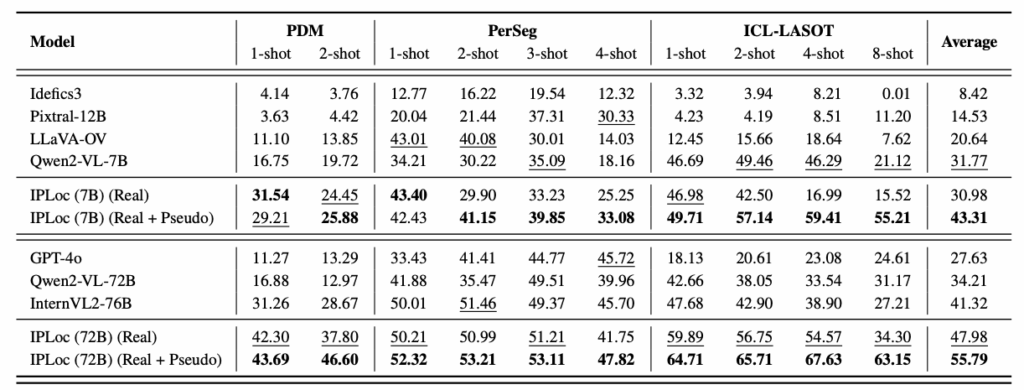
Performance comparison of IPLoc. Source: the paper.
While GPT-4o provided strong descriptive explanations, it performed poorly in predicting actual coordinates. In contrast, the Qwen2-VL model showed a clear improvement after applying IPLoc: its average IoU increased from 31.8% to 43.3%, and for the larger 72B-parameter version, performance rose further to 55.8%. Even models of the same size demonstrated roughly 20% higher accuracy when trained with IPLoc compared to those without it.
However, the approach also comes with clear limitations. Currently, IPLoc can detect only one object at a time, which means its performance drops to around 5.3% in multi-object scenarios. This weakness is shared by most existing VLMs. The researchers plan to integrate IPLoc with more powerful multimodal models in the future, enabling them to distinguish and track multiple objects contextually within the same scene.
The true significance of IPLoc lies not in its raw performance but in its learning approach. This study explores how AI can learn through context, much like humans do. It shows that what truly matters is not the size or computational power of a model but the structure and contextual richness of its data.
Looking ahead, this research points to a shift in AI development, from building ever-larger models to creating smarter and more context-aware datasets. In a way, it reminds us that for AI, just like for humans, understanding is more important than memorization.


