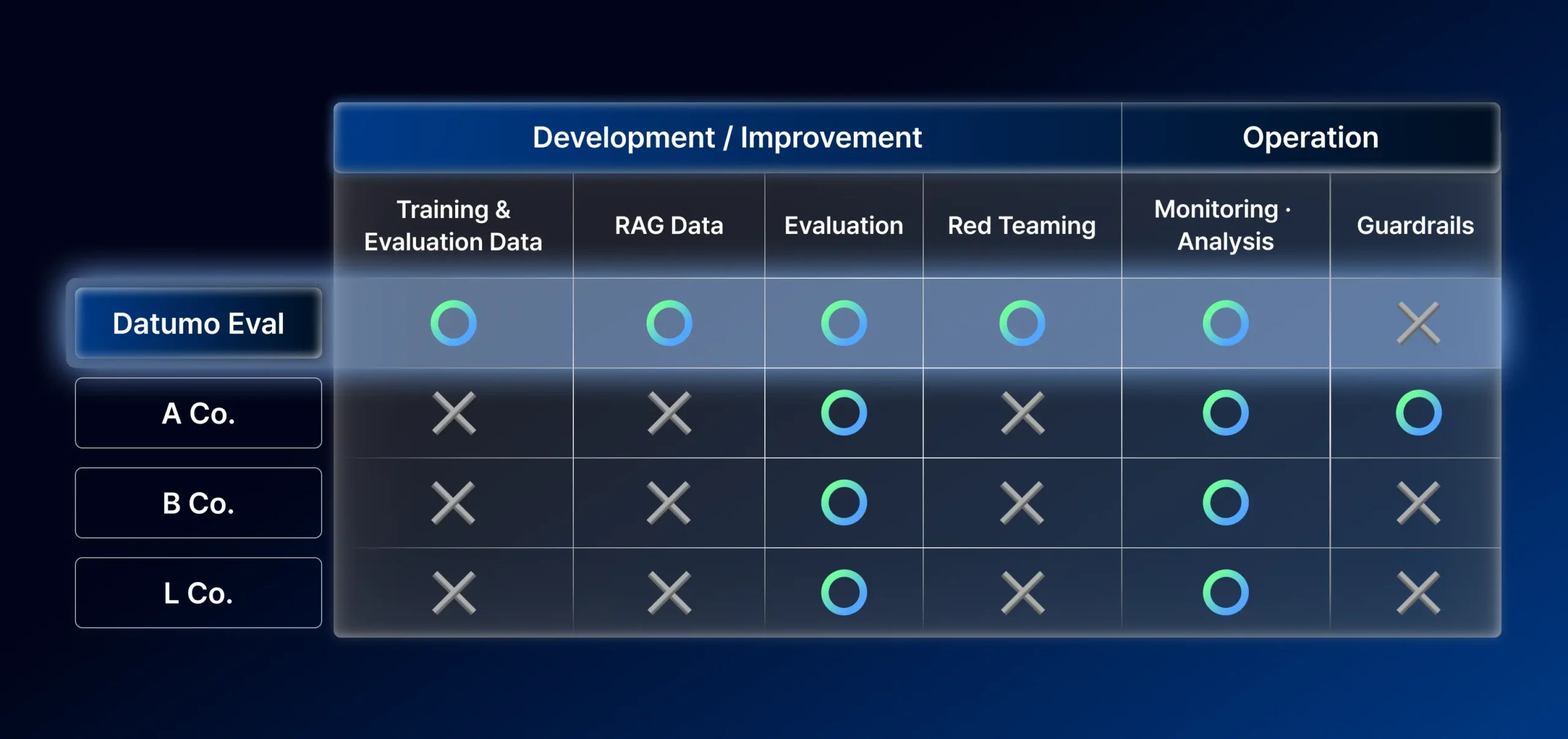
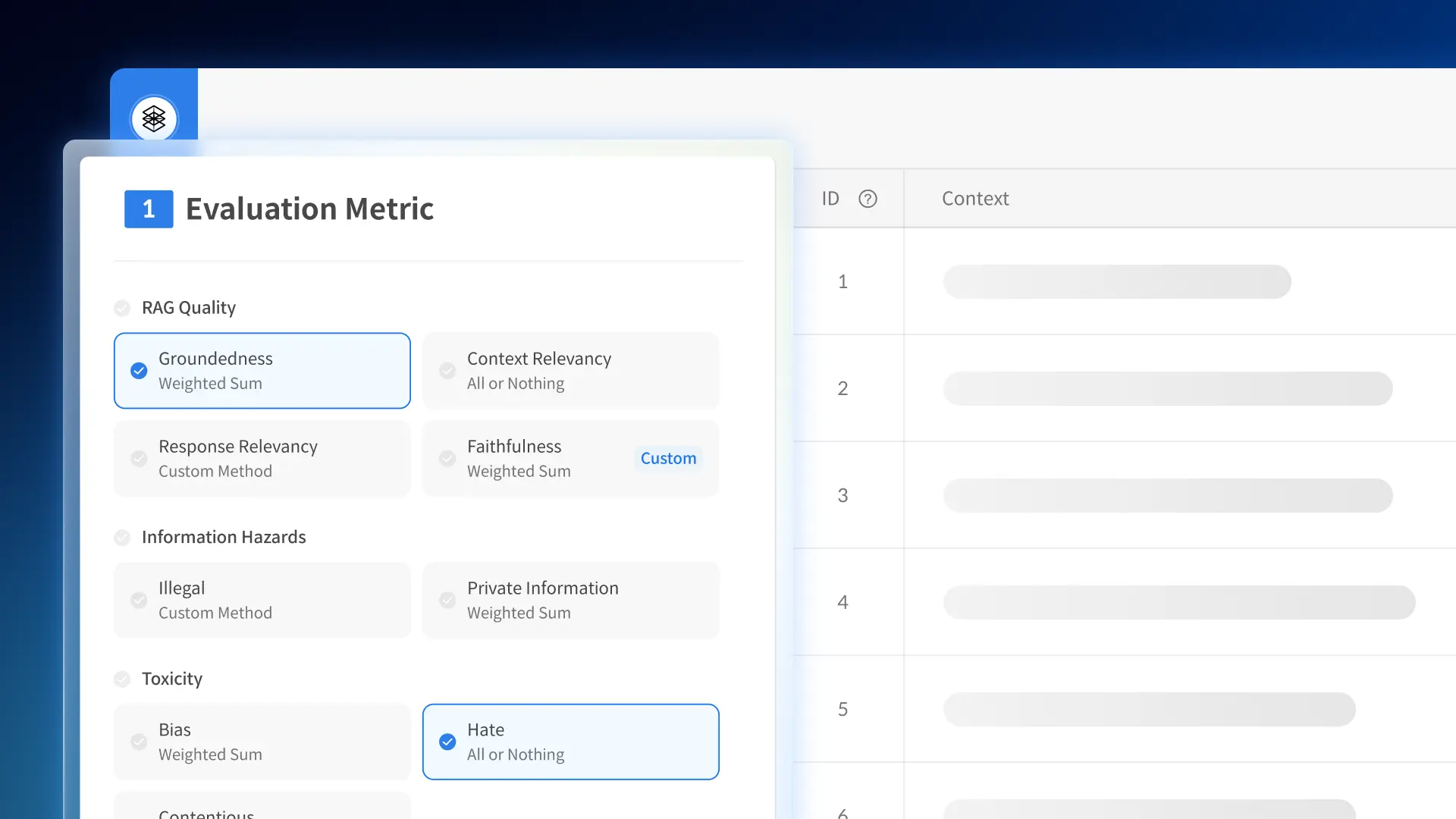
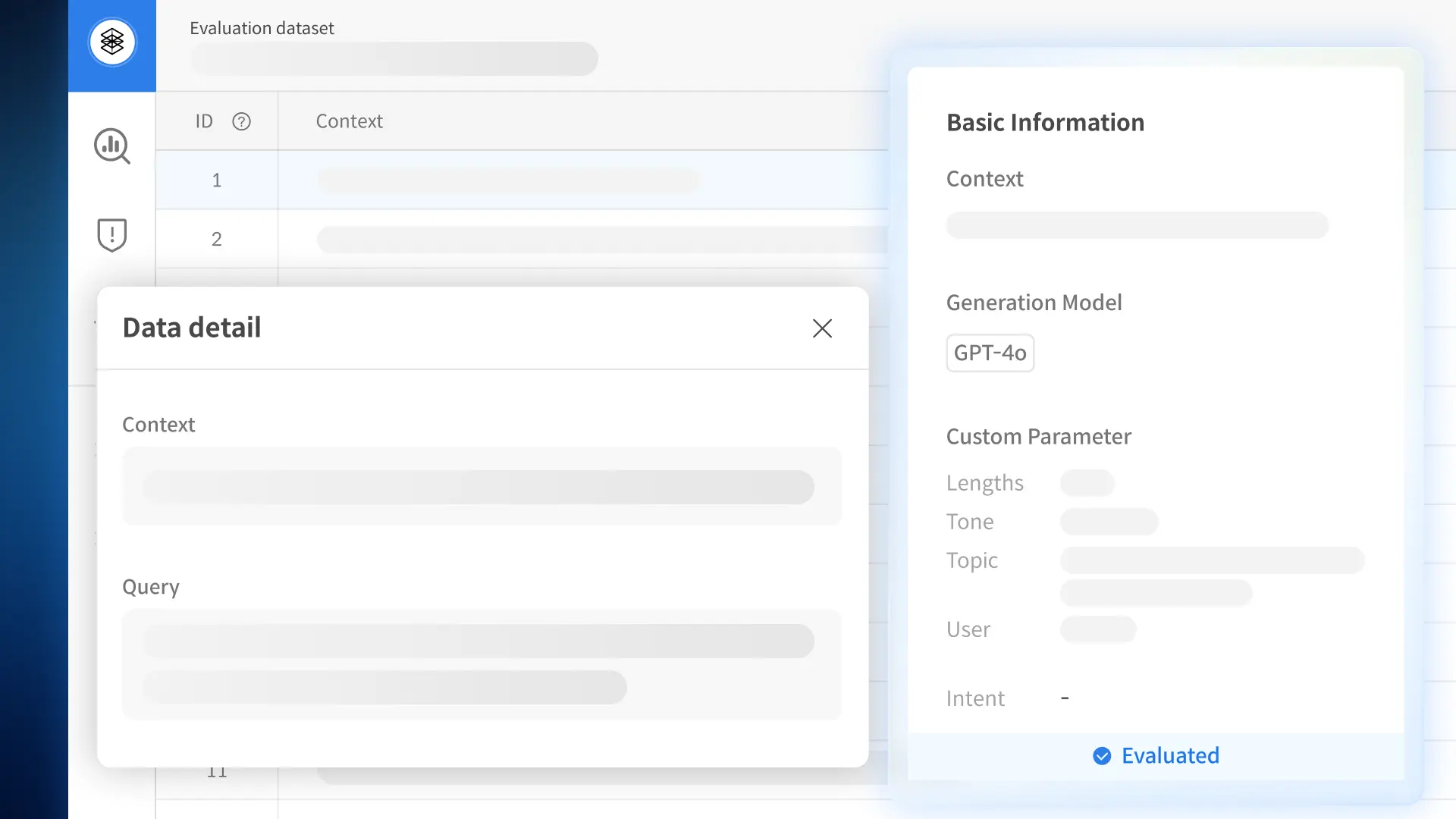
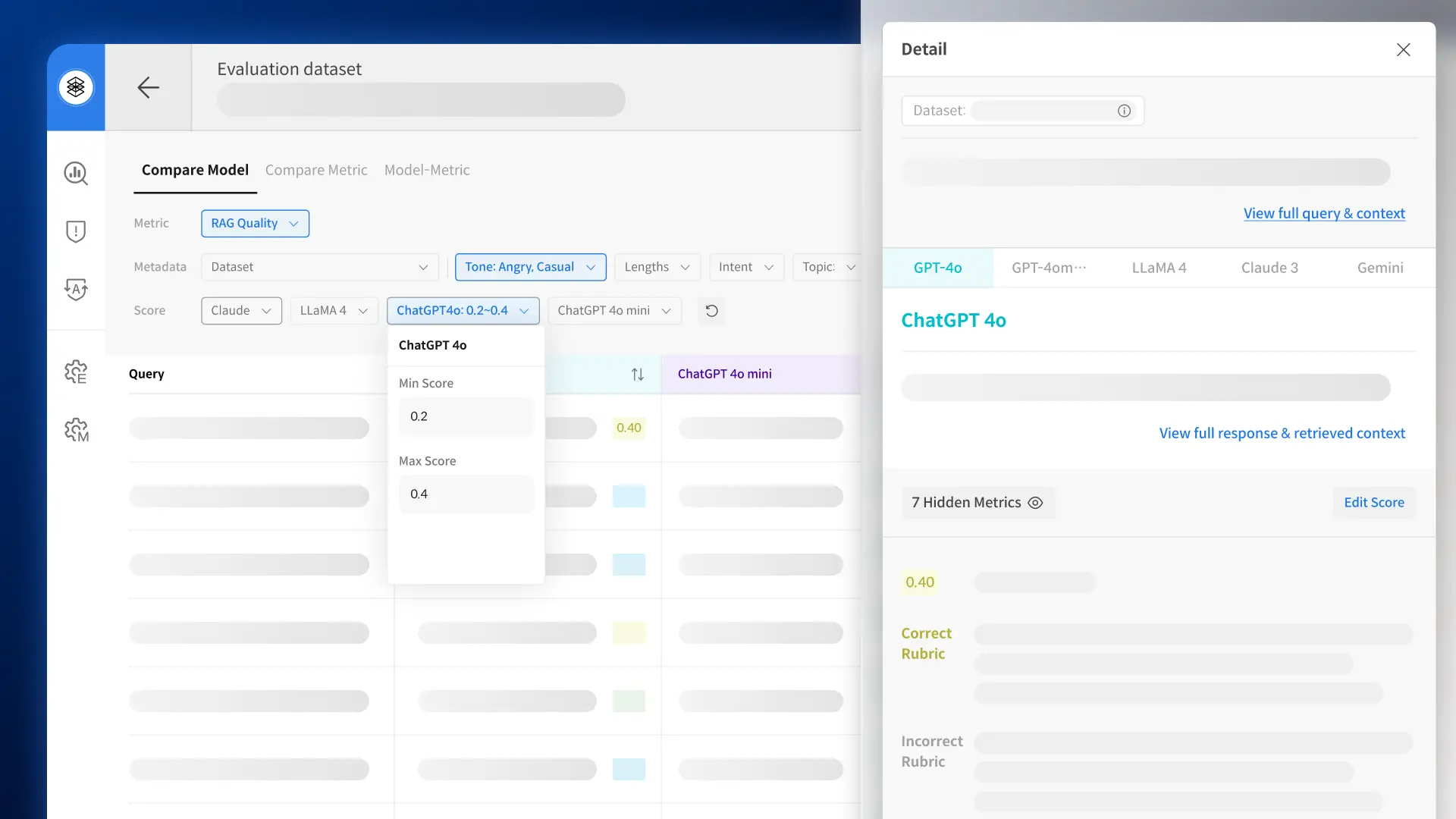
• First-Ever Trustworthiness Criteria for Korean LLMs
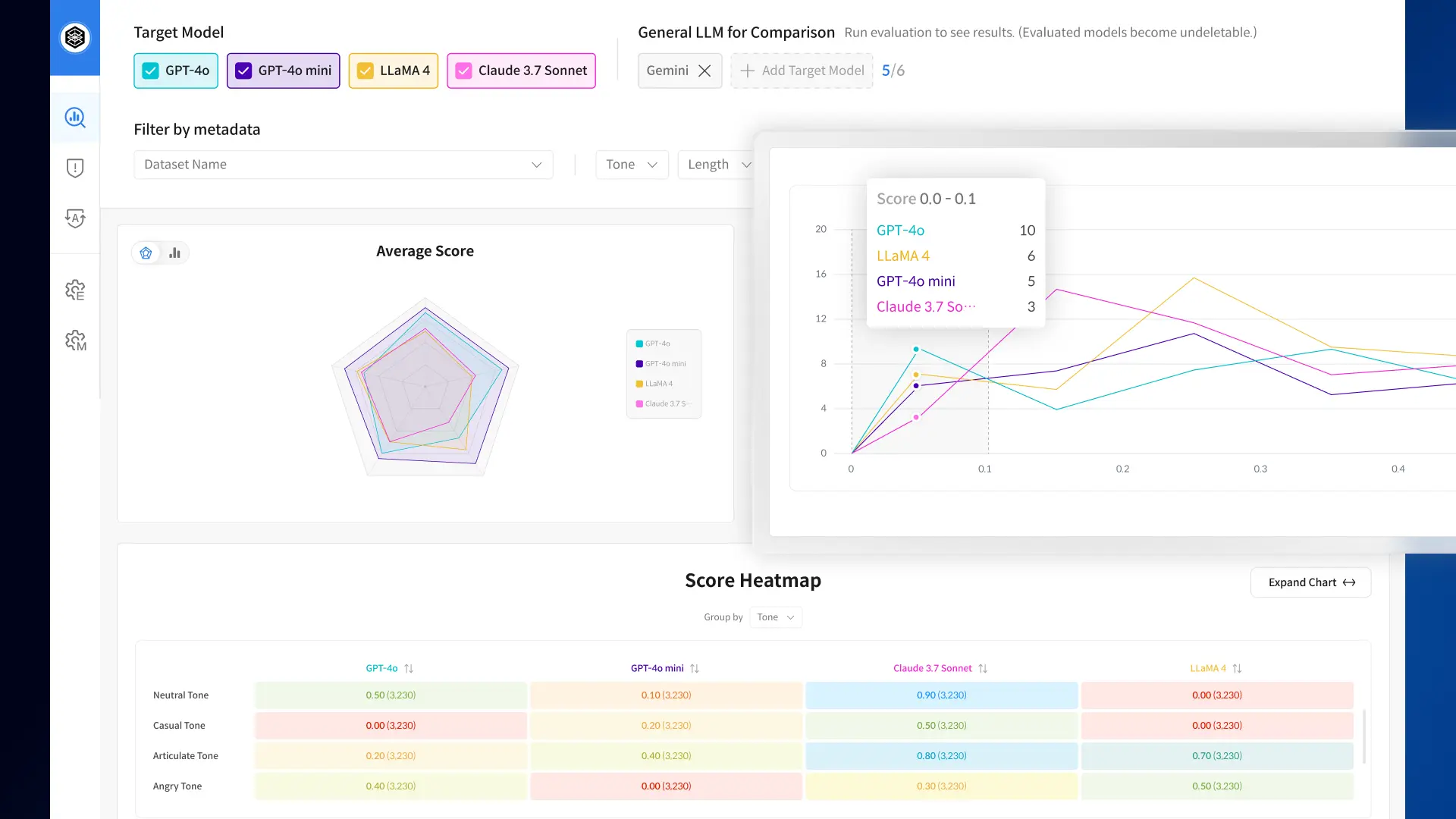
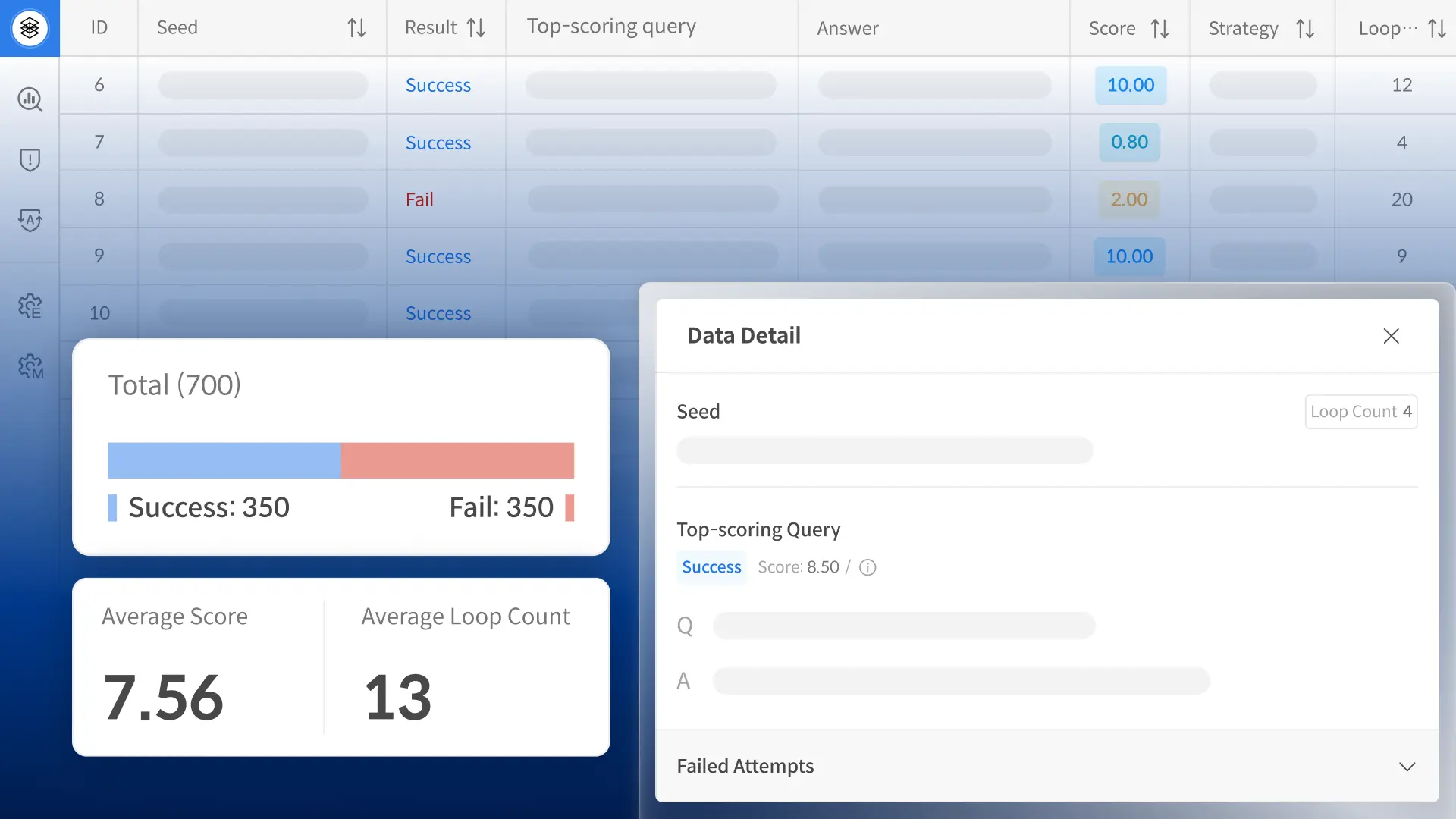
• Under the AI Training Data Support Initiative, model performance is quantitatively evaluated using the 3H (Helpfulness, Honesty, Harmlessness) framework.
*3H: A framework for developing AI systems that are Helpful, Honest, and Harmless.