
What is DeepSeek?
The Llama 4 Herd

The Llama 4 series includes three newly released models:
Llama 4 Scout: 17B active parameters, based on 16 experts. A high-performance lightweight model.
Llama 4 Maverick: 17B active parameters, based on 128 experts. A versatile model specialized in multimodal tasks and coding.
Llama 4 Behemoth: 288B active parameters, totaling 2 trillion parameters (still in training, not yet released).
Among these, Behemoth served as the “teacher” model for Scout and Maverick. As a massive model, Behemoth transferred advanced reasoning, coding, and multimodal understanding abilities during the training process.
Scout and Maverick have been released with open weights, meaning anyone can download, fine-tune, or adapt them. However, since the training code and datasets have not been released, they are not fully open-source.
The Technology Behind
1. Mixture-of-Experts (MoE) Architecture
Both Llama 4 Scout and Maverick adopt Meta’s first-ever Mixture-of-Experts (MoE) architecture.
Scout has 16 experts, and Maverick has 128. Experts refer to small specialized networks selectively activated based on the input. Instead of using all experts simultaneously, only a subset is triggered per input, achieving both high efficiency and strong performance.
Thanks to this design, both models boast excellent compute efficiency relative to their capabilities—and they can be operated even on a single NVIDIA H100 server.
2. Natively Multimodal Models
Scout and Maverick were designed from the ground up to be multimodal, capable of processing both text and images. They use an early fusion method to combine text tokens and image patches into a shared input stream over a single backbone.
Both accept up to 48 images as input and support grounding tasks, linking specific image regions with textual queries, making them strong at multi-image reasoning and vision-language tasks.
3. 10M Token Ultra-Long Context
Scout can handle up to 10M tokens of context—a massive leap over Llama 3’s 128K tokens (about 80× longer) and Gemini 1.5 Pro’s 1M tokens (10× longer).
The key is the iRoPE (interleaved RoPE) positional encoding, an extension of rotary positional embeddings.
By applying interleaved attention layers without positional embeddings, the model maintains information fidelity across very long contexts. This enables applications like summarizing hundreds of documents, analyzing large codebases, and performing deeply personalized reasoning based on long user histories.
4. Codistillation: Knowledge Transfer from Behemoth
Scout and Maverick were trained through codistillation from Meta’s internal supermodel Behemoth.
Rather than simply learning correct answers, they learned by mimicking Behemoth’s outputs—including soft labels (full probability distributions)—allowing them to absorb Behemoth’s depth in reasoning, coding, and multimodal understanding.
✋🏼 Quick note!
DeepSeek took a slightly different approach with Knowledge Distillation, where the student gradually reduces reliance on the teacher. In contrast, Llama 4 used Codistillation, where student models continue training alongside the teacher, requiring more compute but achieving higher fidelity to the teacher’s capabilities.
- Codistillation: Requires more compute but results in higher-quality student models
- Knowledge Distillation: More compute-efficient but students may not fully match the teacher’s sophistication.
Only At Meta
- Addressing Bias
Meta invested significant effort into mitigating bias issues in the Llama 4 series.
They reduced the refusal rate on controversial topics from 7% (Llama 3.3) to under 2%, and cut the rate of asymmetrical refusals—where the model would decline responses based on specific viewpoints—to below 1%.
The rate of politically biased answers was also cut by more than half compared to Llama 3.3, bringing the model much closer to a neutral stance. - AI Comes to You
You don’t have to seek out Llama anymore—it’s already by your side.
Meta has integrated Meta AI, powered by the Llama 4 series, into WhatsApp, Facebook Messenger, Instagram, and the Meta.ai website. Llama 4 is beginning to seamlessly blend into the daily lives of billions of users, signaling the start of Meta’s large-scale AI expansion across its global platforms.
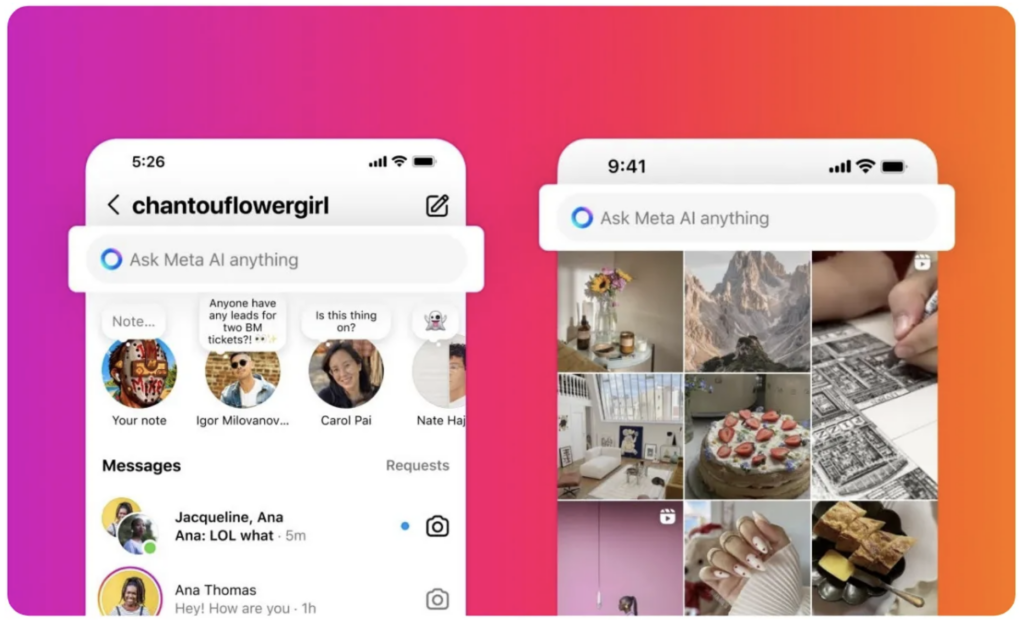
Meta AI on Instragram. Source: Plannthat.com
Sam Altman tweeted recently:
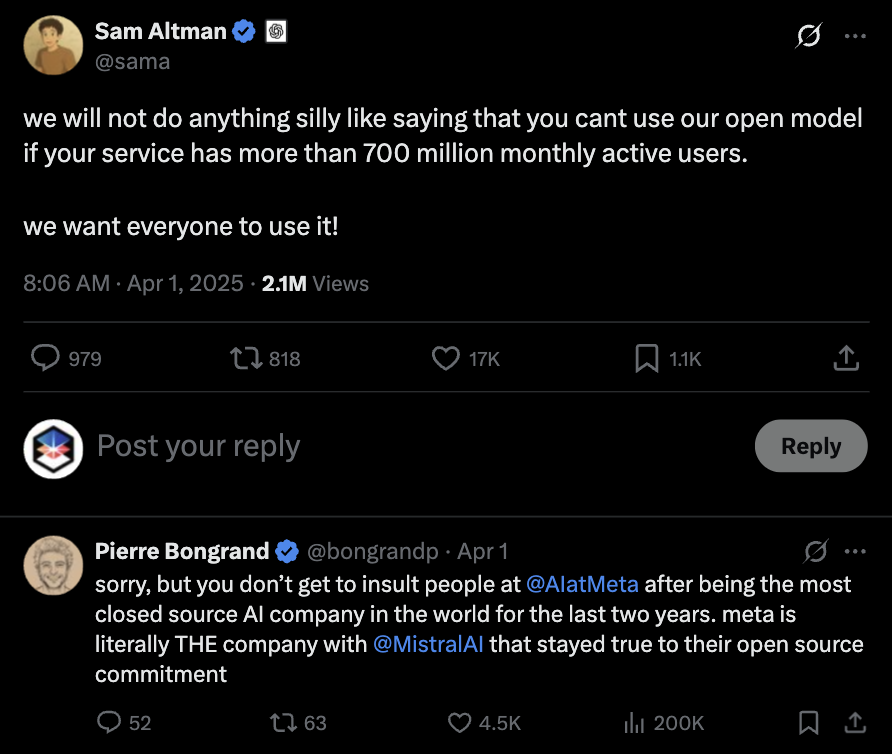
OpenAI is undeniably leading in the generative AI race today. However, we can’t ignore the fact that Meta’s decision to openly share information is helping the entire industry advance. Companies have no obligation to disclose what amounts to their trade secrets. Still, over time, it will become clear who was merely sprinting—and who had their eyes on the whole forest.


