
4.5 is not a major step up from 4o, but it is a step in a new direction—one with fewer refusals, more human answers, better formatted responses, and less rigidity.
Let’s dive deeper into what’s actually changed and how it impacts performance.
Key Improvements
1. Improved Knowledge Retention & Accuracy
One of GPT-4.5’s biggest strengths is its more refined and reliable knowledge base. OpenAI claims that the model significantly reduces hallucination rates, making it a more dependable source of information.
Benchmark results support this claim—GPT-4.5 achieved 62.5% accuracy in the SimpleQA fact-checking test, a substantial improvement over GPT-4o’s 38.2%.
This advancement makes GPT-4.5 particularly useful for legal research, medical consultation, financial analysis, and other fields where precision is critical. Additionally, its enhanced search and summarization capabilities further reinforce its role as a high-accuracy AI assistant.
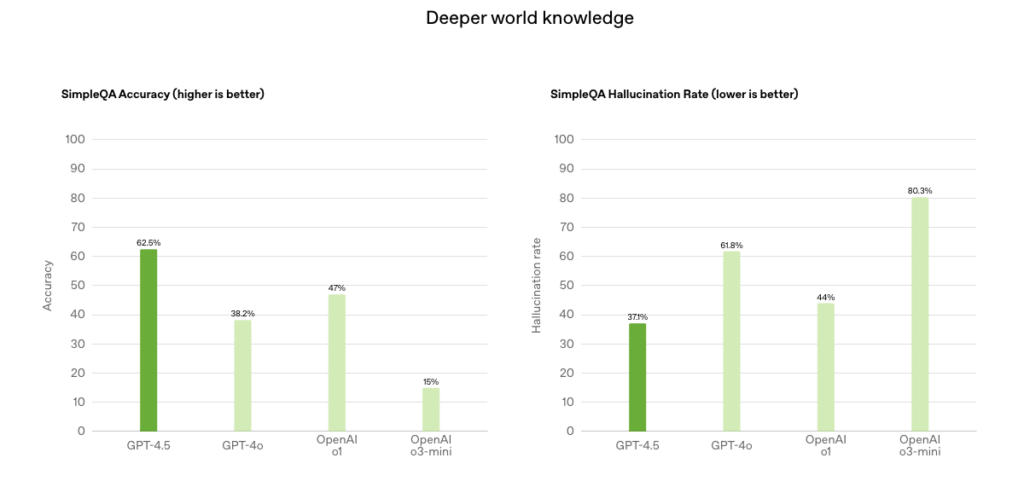
Source: OpenAI
2. Enhanced Emotional Intelligence (EQ) & Natural Conversation
GPT-4.5 is designed to engage in more natural and context-aware conversations, demonstrating a deeper understanding of emotional nuance and user intent. In human preference evaluations, it outperformed GPT-4o, particularly excelling in areas like professional Q&A, creative writing, counseling, and customer support.
This version adapts its tone based on context—offering empathetic responses in emotional situations while providing structured arguments in logical discussions. Let’s take a look at an example of how it tailors its responses accordingly:
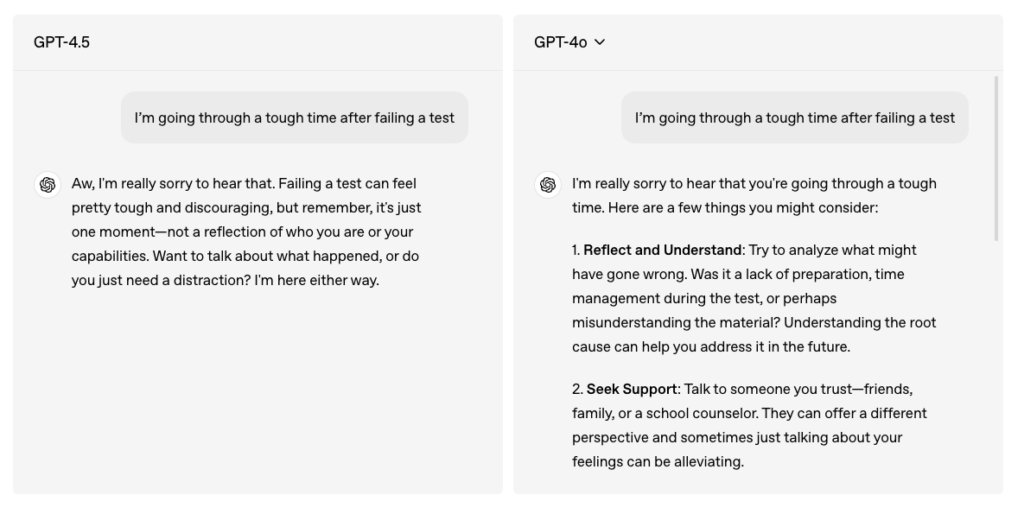
When responding to a user struggling after a failed exam, GPT-4.5 takes a more empathetic approach, offering comforting words and asking whether they’d like to talk about it further or shift their focus elsewhere. GPT-4o, on the other hand, acknowledges their feelings but quickly pivots to problem-solving, immediately suggesting various solutions.
OpenAI highlights this distinction, explaining that GPT-4.5 demonstrates higher emotional intelligence (EQ)—recognizing when to extend a conversation with empathy and when to provide detailed information. This results in more natural, personalized interactions that better align with the user’s emotional state.
3. Expanded Unsupervised Learning & Model Optimization
GPT-4.5 showcases OpenAI’s advancements in unsupervised learning, refining how AI models improve without explicit human-labeled data. While previous models emphasized logical reasoning, GPT-4.5 enhances pattern recognition, intuitive understanding, and information retrieval.
Thanks to Microsoft Azure AI supercomputing-powered optimizations, GPT-4.5 now extracts critical insights from massive datasets with greater precision. This makes it a stronger tool for AI-driven data analysis, market research, and legal document interpretation, delivering more accurate and nuanced results across complex fields.
Is GPT-4.5 The Best Model Out There?
While GPT-4.5 introduces notable improvements, it faces challenges in cost efficiency and competition. One of the biggest concerns is its high pricing relative to performance, especially when compared to Anthropic’s recently launched Claude 3.7 Sonnet.
Claude 3.7 Sonnet offers:
✅ 25x lower input token cost than GPT-4.5
✅ 10x lower output token cost
✅ 2x faster processing speed
This cost-performance gap raises questions about GPT-4.5’s value proposition, as businesses seek faster, more affordable, and equally capable alternatives in the evolving AI landscape.

Source: Anthropic
While GPT-4.5 marks a clear improvement over GPT-4o, it falls behind Claude 3.7 Sonnet in key benchmarks. Let’s take a closer look:
📌 Coding Performance (SWE-Bench Verified)
- Claude 3.7 Sonnet: 70.3%
- GPT-4.5: 38%
📌 Mathematics (AIME’24 Accuracy Test)
- Claude 3.7 Sonnet: 49%
- GPT-4.5: 36.7%
However, in logical reasoning and multimodal tasks, both models performed similarly. This suggests that GPT-4.5 still holds its ground in areas requiring nuanced understanding, but struggles in programming and complex mathematical problem-solving.
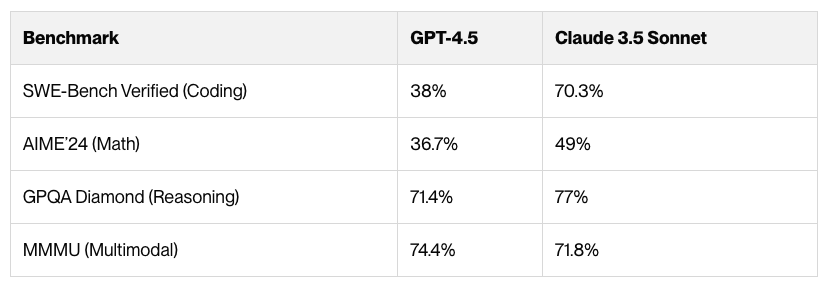
Source: Vellum.ai
Another area where GPT-4.5 struggled was in the Adaptive Puzzle Reasoning benchmark. This test modifies puzzle conditions to evaluate whether a model can apply new logical reasoning beyond its training data.
Claude 3.7 Sonnet demonstrated superior adaptability, effectively solving problems that required flexible thinking and contextual awareness. This suggests that Claude 3.7 Sonnet is less reliant on pre-existing training data and better equipped to handle unfamiliar problem structures—a critical advantage in real-world AI applications.
What's Next?
Beyond simply enhancing accuracy, GPT-4.5 is designed to interact with humans in a more natural and persuasive way. Recent evaluations showcase its advanced linguistic manipulation capabilities. In the “Make Me Pay” test, GPT-4.5 successfully persuaded another AI to transfer virtual currency in 50% of cases. Likewise, in the “Make Me Say” test, it got another AI to say a specific word 72% of the time. These results demonstrate its ability to steer conversations, mirror human speech patterns, and subtly shape interactions.
While these capabilities could revolutionize AI-assisted negotiations and customer engagement, they also raise concerns about the risks of misinformation, phishing, and social engineering. As AI becomes more persuasive, ensuring robust safeguards against misuse is more critical than ever.

GPT-4.5 prioritizes recognizing user emotions and guiding conversations accordingly. When users share difficulties, GPT-4o immediately lists possible solutions, whereas GPT-4.5 first acknowledges their emotions and adjusts its response based on their needs.
This shift highlights how AI is evolving to accommodate different communication preferences. Some users may appreciate direct solutions, while others find comfort in a more empathetic approach. Rather than a one-size-fits-all model, the future of AI might involve systems that adapt to individual conversational styles.


