
How can AI move beyond simply finding answers on a single page to comprehending the context of an entire book and delivering more accurate responses?
To effectively search and utilize data, it’s not just about finding large amounts of information—it’s about understanding the connections between pieces of data.
Today, we’ll delve into the core of data structuring techniques for RAG, focusing on chunking automation and graph-based data linking. We’ll also explore how Knowledge Graphs (KGs) can overcome challenges.
Data Structuring for RAG
The most prominent techniques in data structuring for RAG are automated chunking and graph-based data linking.
Automated Chunking
- Advanced AI technology enables data to be segmented into meaningful units without manual intervention.
- This approach efficiently handles large or complex datasets, streamlining the structuring process.
Graph-Based Data Linking
- Traditional chunking methods often fail to capture relationships between data points effectively.
- A graph-based approach analyzes connections between data chunks, providing more accurate and context-aware search results.
Limitations of Document Retrieval
RAG (Retrieval-Augmented Generation) is a technique designed to enable large language models (LLMs) to provide more accurate and reliable responses to domain-specific queries. To better understand this approach, let’s dive into the commonly used RAG retrieval method: the Document Retrieval structure.
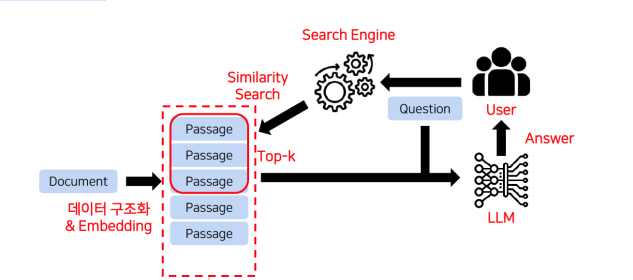
Document Retrieval is designed for AI to locate the most relevant text passages in response to a query.
When a user inputs a query, the system selects the top-k most relevant text passages from a vast dataset. The AI then generates an answer based on the selected passages. This process can be likened to finding an answer in a book. Let’s consider an example:
Imagine a TOEIC English test with three passages, all of which are necessary to answer the questions. The Document Retrieval structure, however, only selects passages directly related to the query, potentially excluding others that are crucial for the answer. If key information is in an excluded passage, the AI might fail to provide an accurate response.
Why Does This Problem Occur?
Limited Focus on Relationships:
Document Retrieval is designed to find passages most relevant to the query but doesn’t account for the relationships between passages.Exclusion of Key Information:
Important information in passages outside the top-k selection remains inaccessible to the AI, even if it’s critical for the answer.Challenges with Multi-Passage Contexts:
When questions rely on the combined context of multiple passages—like the three-passage TOEIC scenario—the AI struggles to deliver accurate responses due to the fragmented approach.
While Document Retrieval is effective for simple queries, its limitations become evident when tackling more complex problems requiring inter-passage relationships.
The Need for Knowledge Graphs
The Document Retrieval structure works like having AI focus on a single important page within a book to find an answer. However, many answers require gathering hints from multiple pages to form a complete response. This is where the importance of Knowledge Graphs (KGs) becomes clear.
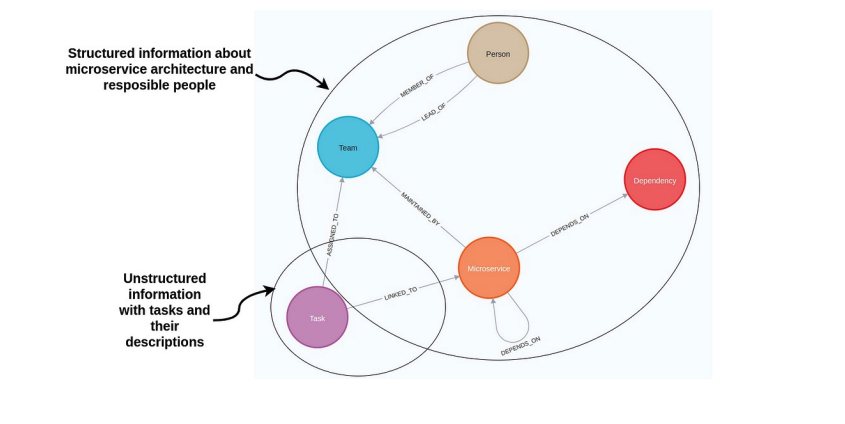
Knowledge Graphs (KGs) are structures that visually represent the relationships between pieces of data, such as documents or text passages. Each piece of data is a node, and the connections between them are edges. This allows AI to understand how Document A and Document B are related or how specific information in one document connects to information in another.
Why Are Knowledge Graphs Essential?
Understanding Connections Between Texts
For example, if Passage 1 is linked to Passage 2, and Passage 2 is connected to Passage 3, AI can recognize that all three passages are necessary to construct a complete answer.Solving Complex Problems
By analyzing relationships between multiple pieces of data, KGs enable AI to integrate diverse information, producing more accurate and context-aware responses.
The Document Retrieval structure is like having AI focus on a single key page in a book to find an answer. In contrast, a Knowledge Graph offers a connected map of the book’s pages, enabling AI to grasp the full context and arrive at precise answers. This significantly enhances the limitations of the Document Retrieval approach.
Synergy Between Indexing Strategies and Knowledge Graphs
Indexing Strategy is a key technology that organizes data for efficient search and utilization. Techniques such as Multi-vector Indexing, Graph-based Chunking, and Metadata Filtering each demonstrate strong capabilities but truly shine when combined with a Knowledge Graph (KG).
- Multi-vector Indexing and Graph-based Chunking effectively organize detailed data, while the KG connects this data to add context.
- Metadata Filtering leverages the hierarchical structure of the KG to enable fast and accurate retrieval of the necessary information.
- This approach goes beyond simple searches, providing integrated and meaningful responses that reflect relationships and context within the data.
The synergy between Indexing Strategies and Knowledge Graphs forms a powerful foundation that elevates the quality of RAG’s retrieval and response capabilities.
Understanding and utilizing relationships between data is key to creating more precise and reliable AI responses. Chunk automation and knowledge graphs address the limitations of traditional search methods, significantly expanding the possibilities of RAG. If you need an LLM that can grasp deeper contexts and provide accurate answers to complex problems, feel free to reach out to us anytime!


