
RAG (Retrieval-Augmented Generation) has become a crucial technology for enabling more precise AI responses. Its strength lies in generating tailored answers using specialized domain knowledge.
At the heart of this process is the structuring and efficient retrieval of data. In this article, we’ll take a closer look at chunking techniques, an essential part of data structuring for RAG systems.
What is Data Structuring?
Data structuring refers to systematically organizing data so that AI can effectively understand, process, and retrieve it. Documents in various formats—such as PDFs, Excel sheets, and text files—must be divided into appropriate segments and arranged in a way that allows AI to quickly search and utilize them.
Since the core of RAG lies in retrieving and combining data, understanding how the data processing workflow operates is essential.
Full-Stack Data Retrieval
To grasp how RAG handles data, it’s important to understand Full-Stack Data Retrieval.
This term describes the end-to-end methodology for managing data within RAG systems. It encompasses every stage of data processing, from initial ingestion and structuring to retrieval and integration during response generation.
In short, Full-Stack Data Retrieval provides a comprehensive view of how data flows through the RAG pipeline, ensuring seamless and accurate information retrieval and utilization.
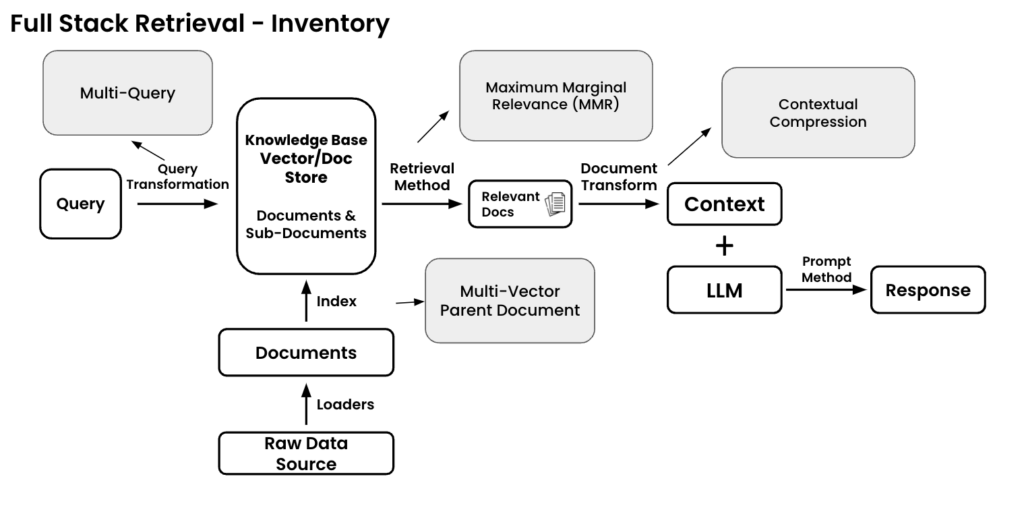
What is Full-Stack Data Retrieval?
Full-Stack Data Retrieval refers to the entire pipeline of how RAG processes and retrieves data. It plays a crucial role in establishing a fast and efficient relationship between search queries and data structures to ensure accurate responses.
1. Query Input
- The process starts with a user question (prompt).
- This query acts as the starting point for data retrieval.
2. Original Data Sources
- These include documents, databases, PDFs, Excel sheets, and other data formats.
- At this stage, the system begins extracting relevant data from these sources.
3. Loader (Chunking Strategy)
- Data undergoes a chunking process, where it is broken down into smaller, meaningful segments.
- This makes the data more manageable and easier for AI to process.
4. Documents
- The chunked data is organized into document units.
- These documents are prepared for indexing to enable efficient search and retrieval.
5. Indexing (Data Structuring)
- Chunked documents are indexed for efficient retrieval.
- The structured data is stored in vector or document databases to facilitate fast searches.
6. Knowledge Base (Vector/Document Storage)
- The indexed data is stored in a knowledge base.
- This repository allows the system to quickly identify and retrieve data relevant to the query.
7. Retrieval Method
- The user’s query is converted into a vector format.
- The vectorized query is then compared with the stored data vectors using similarity methods (e.g., cosine similarity).
- The most relevant data is selected and returned in document form.
8. Context Generation & Response
- The retrieved documents are prepared for generating a response.
- These documents are assembled into context, which is then fed into the LLM (Large Language Model).
- The LLM generates an optimized response based on the given context and the original query.
In Summary:
Full-Stack Data Retrieval ensures a seamless flow—from the initial user query to document retrieval, context formation, and final response generation. Each step plays a key role in enhancing the accuracy, speed, and relevance of AI-generated answers.
What is Chunk Optimization?
In the data processing pipeline described earlier, various techniques are essential to ensure efficiency and accuracy in information retrieval. These include:
- Recursible Retrieval: Iteratively refining search results for better accuracy.
- Hybrid Retrieval: Combining multiple retrieval methods (e.g., keyword-based and vector-based search).
- Re-ranking: Sorting retrieved results based on relevance.
- Decoding Tuning: Fine-tuning the decoding process for more precise responses.
For these techniques to operate effectively, the original data must undergo a Chunk Optimization process.
Chunk Optimization refers to preparing and structuring data chunks in a way that makes them easier to search, retrieve, and process by the AI model.
In short, well-optimized chunks act as the foundation for efficient retrieval, ensuring the AI can quickly and accurately access relevant information during the RAG process.
Chunk Optimization is the process of dividing data into appropriately sized segments to ensure AI can effectively understand, search, and utilize the information.
The goal isn’t just to split data arbitrarily but to group semantically related content into dense, meaningful chunks. The higher the information density of each chunk, the more accurately AI can respond to queries. Additionally, efficient chunking allows models to handle larger prompt sizes while still delivering compact, context-rich information.
Token Overlap
- Poor chunking can result in information loss.
- Token Overlap prevents this issue by overlapping tokens across adjacent chunks, ensuring critical details are preserved even when data is split into segments.
Key Chunking Strategies:
Fixed-Size Chunking:
- Divides data into uniform, fixed-length chunks.
- Pros: Simple and easy to implement.
- Cons: May split meaningful content across chunks.
Document-Based Chunking:
- Splits data based on the document’s inherent structure (e.g., paragraphs, sections).
- Pros: Preserves natural context.
- Cons: May result in inconsistent chunk sizes.
Semantic Chunking:
- Divides data based on semantic meaning rather than fixed size or structure.
- Pros: Ensures each chunk retains a meaningful context.
- Cons: More resource-intensive to implement.
Agentic Chunking:
- An advanced approach that analyzes and divides data based on key propositions or actionable insights.
- Pros: Highly optimized for complex, query-focused scenarios.
- Cons: Requires more sophisticated processing techniques.
Why Chunk Optimization Matters
Effective chunk optimization is critical for:
- Enhancing search accuracy: AI can retrieve and use data more effectively.
- Reducing information loss: Token overlap minimizes missed details.
- Improving response quality: Dense, well-structured chunks lead to more precise answers.
In short, chunk optimization serves as the backbone of RAG’s data processing pipeline, bridging the gap between raw data and meaningful AI outputs.
In RAG, data structuring and chunk optimization are essential steps for enabling AI to generate precise and refined answers. By dividing data into meaningful chunks and organizing it systematically, AI can search, retrieve, and utilize information more efficiently. Techniques like Semantic Chunking and Token Overlap significantly enhance both data retrieval and response generation, ensuring smoother and more accurate outcomes.
In our next article, we’ll take a deeper dive into Chunking & Indexing, analyzing chunking strategies at various levels. We’ll explore which chunking strategies are most effective in different scenarios and how the integration of chunking and indexing can maximize RAG’s performance. Stay tuned!
Image Source: https://community.fullstackretrieval.com/introduction/retrieval-inventory


