
Evaluating quality text in the field of Natural Language Generation (NLG) has always been challenging. Assessing text quality to align with human intuition becomes particularly complex for creative or open-ended tasks. Traditional metrics like BLEU and ROUGE are useful for quantifying performance but fall short of capturing the diversity and creativity required in tasks like dialogue or summarization.
In May of last year, G-EVAL emerged as an innovative framework leveraging GPT-4’s advanced language understanding to deliver results closer to human evaluation. How has this new paradigm shifted NLG evaluation methods?
The Purpose & Importance
G-Eval introduces a new approach for evaluating model-generated text using a “form-filling” prompt-completion method. This is a widely used approach within LLM-as-a-Judge frameworks, where evaluations are driven by prompts. Generally, there are four main components in prompt-based evaluations:
1. Task instruction
2. Evaluation criteria
3. Input contents
4. Evaluation methods
2. Evaluation criteria
3. Input contents
4. Evaluation methods
The entire prompt is structured around these elements and then submitted to the LLM for evaluation. In G-Eval, task instructions and evaluation criteria are crafted by humans, while evaluation methods are automatically generated using Chain-of-Thought (CoT) reasoning. Since evaluation methods can be complex and time-consuming to design manually, CoT enables rapid processing. Finally, the actual model-generated text (Input contents) is added, and the LLM performs the final evaluation. This innovative approach makes G-EVAL one of the most human-aligned evaluation tools currently available.
The Framework
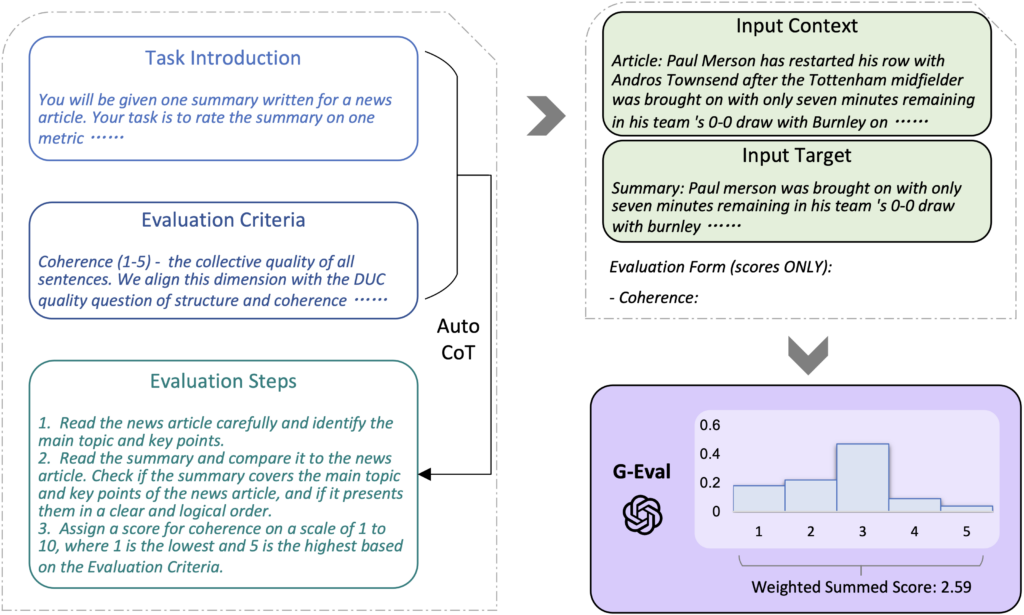
The overall framework of G-EVAL.
The G-EVAL framework consists of three core components:
- Prompt Definition: Each evaluation task begins with a clearly defined prompt, specifying criteria like coherence or relevance. Task instructions and evaluation criteria are crafted manually.
- Creating Evaluation Steps with Chain-of-Thought (CoT): Using the Task Instruction and Evaluation Criteria generated above, CoT reasoning is applied to develop Evaluation Steps.
- Probability-Based Scoring Function: Unlike traditional methods, G-EVAL applies probabilistic weighting to each evaluation criterion, capturing finer nuances in scoring. This approach enhances alignment with human judgment and better reflects subtle differences between generated texts.
The Benchmarks
G-EVAL has been rigorously tested on three benchmarks: SummEval, Topical-Chat, and QAGS. Let’s take a look:
- Summarization: In the SummEval test, G-EVAL demonstrated a high correlation with human evaluations in terms of coherence, fluency, and relevance, significantly surpassing traditional metrics.
- Dialogue Generation: For conversational consistency and engagement in the Topical-Chat benchmark, G-EVAL achieved results closest to human judgment.
- Hallucination Detection: On the QAGS benchmark for evaluating summary consistency, G-EVAL outperformed models like BERTScore and ROUGE, especially excelling in complex, abstract summaries.
These results demonstrate G-EVAL’s superior alignment with human evaluations across various tasks, establishing it as a more reliable evaluation tool than traditional models that often lack multidimensional adaptability and nuanced scoring.

The Difference
G-EVAL’s new Chain-of-Thought (CoT) methodology represents a significant departure from previous models. While traditional models like GPTScore or BARTScore follow fixed evaluation methods, G-EVAL offers a more in-depth analysis through a detailed evaluation structure. Its probability-based scoring allows for more precise assessments than discrete models like UniEval. Thanks to its comprehensive form-filling approach, G-EVAL doesn’t just assign scores—it evaluates with human-like standards.
Key Findings and Researchers’ Conclusions
- Higher Human Alignment: G-EVAL excels in aligning with human evaluations, making it an effective tool, especially for subjective tasks.
- Potential Bias Toward LLM-Generated Text: The study highlights a potential bias where LLM evaluators may favor machine-generated over human text, underscoring the importance of ensuring that future evaluation frameworks do not inherently prefer AI-generated content.
- Effectiveness of CoT Reasoning: The researchers emphasize that CoT significantly enhances quality in complex tasks, suggesting that CoT could become widely used in AI evaluations moving forward.
The Future
As G-EVAL shapes the future of NLG evaluation, it holds the promise of more accurate, human-aligned assessments that support high-quality language model development. By addressing potential biases and maintaining a balanced approach, G-EVAL paves the way for AI to become a trusted partner in creating more meaningful and reliable natural language generation. The continued refinement of evaluation methods like G-EVAL will be essential as NLG technologies expand across diverse applications, ensuring that AI remains both innovative and aligned with human values.


