
The rise of large language models (LLMs) has revolutionized many industries, providing businesses with more efficient ways to retrieve and generate relevant information through retrieval-augmented generation (RAG). As the variety of LLMs grows, companies face new opportunities and challenges in deciding which models best fit their RAG tasks.

Understanding RAG Tasks and Their Importance
RAG tasks are essential in various industries, such as customer service, legal analysis, and academic research. These tasks combine information retrieval and generation to offer precise, context-driven responses. Whether it’s a chatbot delivering customer support or a legal team analyzing large documents, RAG systems play a pivotal role in streamlining these processes.
But as RAG tasks become more complex, LLM reliability and evaluation methods take center stage. Companies must navigate challenges like choosing the right LLM, managing large datasets, and ensuring reliable and scalable workflows through well-defined metrics.
Evaluating LLMs for RAG Tasks: Key Methods and Metrics
To ensure that the LLMs used in RAG tasks are effective, businesses need to focus on LLM evaluation methods that test their performance across different contexts. Evaluation metrics such as accuracy, token usage, context adherence, and the rate of hallucinations are critical for determining LLM reliability. These metrics provide insights into how well models perform in short, medium, and long-context RAG tasks.
For short-context RAG (SCR) models, metrics like ChainPoll assess a model’s ability to adhere to the context without introducing errors. Medium-Context RAG (MCR) and Long-Context RAG (LCR) models require more complex evaluation tools, focusing on how well the model maintains relevance and accuracy over longer sequences.
The choice of evaluation methods and metrics helps businesses identify the most reliable LLM for their specific needs, ensuring the quality of both retrieval and generation in RAG workflows.
Types of RAG Models
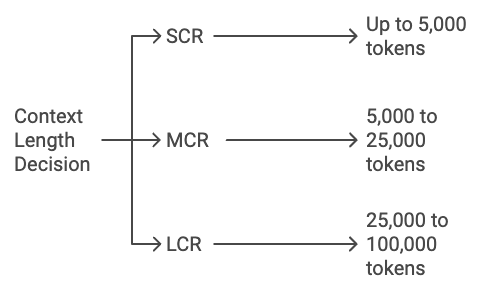
RAG tasks can be categorized based on the amount of context the model handles:
- Short-Context RAG (SCR): SCR models are ideal for scenarios requiring concise, quick responses, such as customer service or knowledge-base queries. They typically process up to 5,000 tokens, making them perfect for live chat systems or basic customer interactions.
- Medium-Context RAG (MCR): MCR models handle between 5,000 and 25,000 tokens and are well-suited for more in-depth tasks like academic research. These models can process larger amounts of information without sacrificing speed and efficiency.
- Long-Context RAG (LCR): LCR models, which can manage up to 100,000 tokens, are built for highly complex tasks, such as analyzing legal documents or generating reports from large datasets. However, they come with higher costs, especially when factoring in the increased computational power and storage required.
Understanding these categories and applying the right evaluation metrics ensures that LLMs can meet the specific needs of each RAG context, optimizing workflows and managing costs effectively.
Cost and LLM Reliability in RAG Workflows
One of the major cost drivers in RAG workflows is the use of vector databases. These databases store vast amounts of data for rapid retrieval, but as datasets grow, maintaining them becomes more expensive. For enterprises handling extensive RAG tasks, LLM reliability is crucial, as errors or inefficiencies can lead to increased operational costs.
LCR systems are emerging as a solution to reduce reliance on expensive vector databases. By processing larger chunks of information at once, LCR models can lower costs while maintaining accuracy and efficiency in both retrieval and generation.
Why Open-Source LLMs Are Gaining Popularity for RAG Tasks
As enterprises look for ways to improve efficiency and reduce costs, open-source LLMs have become an attractive option for RAG tasks. Here’s why:
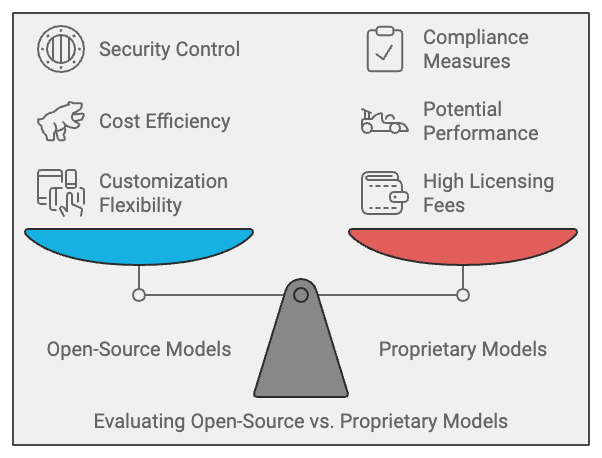
- Customization: Open-source models offer unparalleled flexibility. Companies can tailor models to their specific needs, optimizing them for industry-specific use cases. For example, a customized LLM for customer support might improve response speed and accuracy by up to 30%.
- Cost Efficiency: Proprietary models often come with high licensing fees. Open-source alternatives, such as the Llama-3-70b-Chat model, eliminate these fees and provide the same—or even better—performance. Businesses can save significantly on operational costs without compromising quality.
- Security and Compliance: Many industries require strict data security and compliance measures. Open-source LLMs provide enterprises with the control needed to audit, manage, and secure their data effectively.
In conclusion
Optimizing RAG tasks with the right LLMs involves understanding the nuances of model selection, evaluation metrics, and the potential benefits of open-source solutions. By leveraging these insights, businesses can enhance their workflows, ensuring efficiency and reliability in their operations.


