
As LLMs have evolved, so have other fields that utilize these models, such as Vision Language Model (VLM). VLMs are a type of multimodal model that combines visual and linguistic information. In everyday life, some information is easily understood visually, while other information can be comprehended through text alone. VLMs effectively combine these two types of information to help users retrieve the desired data.
Vision Language Models in Action
So, in which fields can VLMs be effectively utilized? Language models are already aiding users by acting as Copilots, answering sequential questions to deliver desired results. Adding visual information to this process could enable users to obtain their desired information more quickly and efficiently. This week, we introduce CogAgent, which combines visual data to guide users through tasks on computers or smartphones. Let’s dive into what CogAgent has to offer.
CogAgent
Last month, the paper titled <CogAgent: A Visual Language Model for GUI Agents> was published, focusing on a vision language model designed for Graphical User Interfaces (GUIs). GUIs encompass all graphical elements on a smartphone or PC screen that allow interaction with the computer. Think of the computer screen you’re looking at; that’s a GUI.
Helping users with tasks is not a new concept. In 2023, the AutoGPT model gained fame for autonomously performing desired tasks, albeit based on text data. However, visual icons, images, and diagrams can be challenging to convey through text alone. CogAgent understands visual information and guides users through tasks by indicating precise coordinates on the screen.
Understanding GUIs is a user-centric approach. Early computers required users to input code into a dark screen to run programs, a method known as the Command Line Interface (CLI), which posed significant barriers for many users. GUIs offered a more accessible alternative. If an agent can understand GUIs, it can assist users more effectively. Let’s look at an example.

A user opens Google’s homepage and asks CogAgent, “Could you guide me through the steps to search for the best paper in CVPR 2023?”
CogAgent responds by pointing to the search bar, typing “best paper in CVPR 2023,” pressing Enter, and indicating the relevant information. This process mimics how a human would perform a search. Similarly, CogAgent can understand smartphone screens.
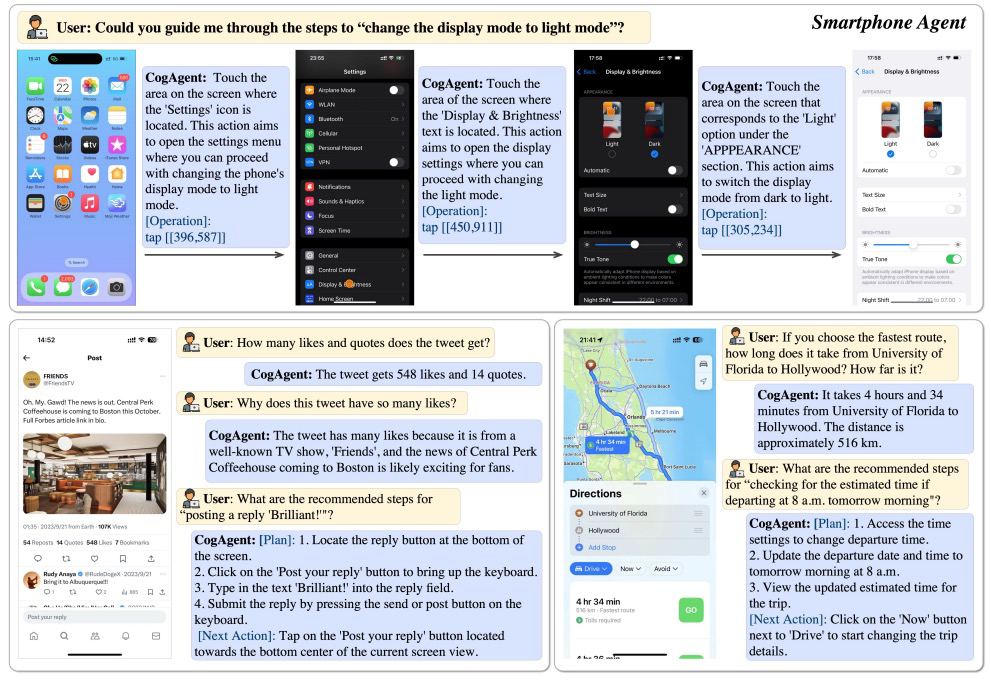
For example, it can switch to light mode, explain why a post has many likes, or find directions based on the user’s schedule.
Developing CogAgent
How did researchers develop a VLM capable of understanding GUIs? They created CogAgent based on their proprietary CogVLM-17B, training it to comprehend GUIs.
Screenshots of web pages are large, containing numerous GUI elements like buttons and input fields. Resizing these screenshots could result in a loss of information. Thus, a model capable of understanding high-resolution images was necessary. Researchers enhanced CogVLM with an image encoder to process high-resolution images.
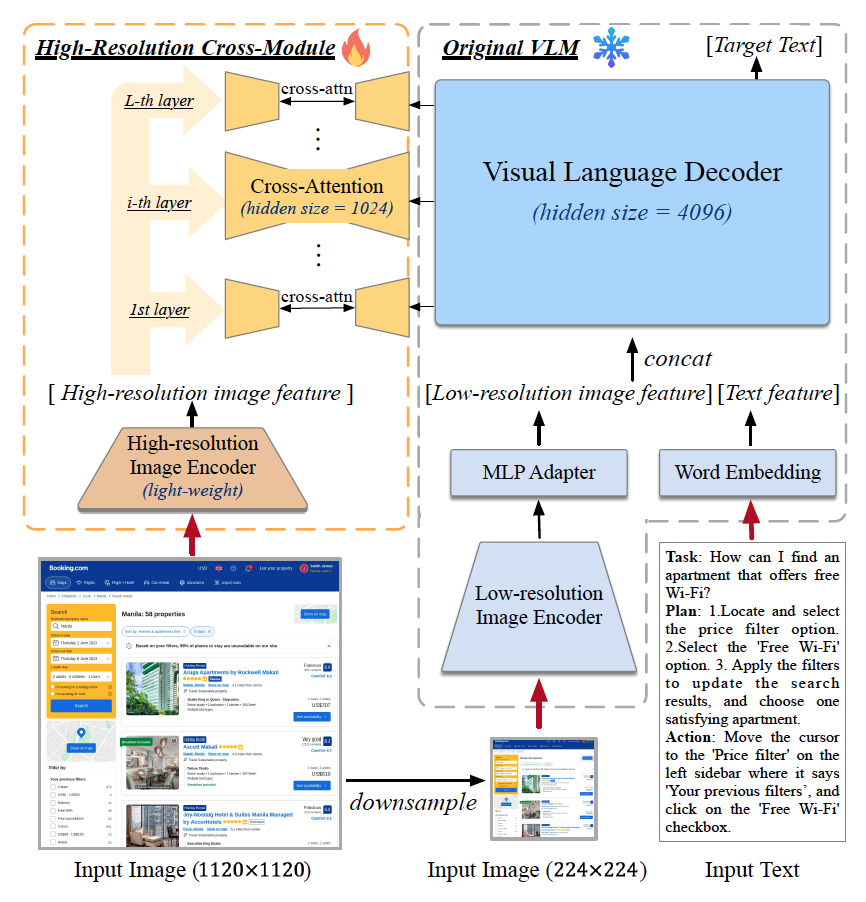
To explain the model structure, the researchers downsampled screenshots to a size understandable by the existing vision language model, inputting text that represents tasks and actions. They then calculated Cross-Attention between the information from the high-resolution image encoder and the downsampled images and text features. Cross-Attention assesses the relevance between different types of information (high-resolution image data and low-resolution image and text data).
Moreover, the vision language model needs to understand what tasks a user might require from each screen. Human labeling is necessary for this, although it’s challenging to label all data manually. Therefore, researchers used GPT-4 to generate questions and answers based on existing web and mobile screenshots.
Since CogAgent operates by visually interpreting screenshots, it must accurately identify the coordinates of selectable elements within the image. This process necessitates extensive training data, resulting in the creation of CogAgent.
Future Prospects of CogAgent
CogAgent, with its enhanced LLM capabilities, can assist users by leveraging visual information beyond text. As an early model, it still has areas for improvement, such as correcting inaccurate coordinates and processing multiple images. However, these issues are expected to be resolved as more data is accumulated and the model’s performance improves.
The critical takeaway is that AI continues to develop to assist in everyday tasks. While CogAgent currently performs tasks based on screenshots, future models that understand video content could provide continuous assistance and more natural interactions. As a result, many researchers are paying attention to this study. With CogAgent set to be open-sourced, we can expect rapid advancements in models that assist with GUIs.


