
Modified National Institute of Standards and Technology, known as MNIST in short, is a dataset containing handwritten images of digits from 0 to 9 (made by the guru, Professor Yann LeCun, and his colleagues). To be more precise, the dataset contains a total of 70,000 square, grayscale images of dimensions 28 x 28 pixels each. Each image comprises 784 features, and each feature corresponds to a pixel’s intensity, which is from 0 to 255. Out of the total 70,000 images in the dataset, 60,000 are for training, and the remaining 10,000 images are for testing. The total number of classes is 10, signifying the output i.e., the digits from 0 to 9 inclusive.


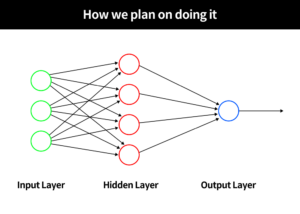
Step 1: Import essential libraries and packages
import tensorflow import tensorflow.keras from keras import models from keras import layers from keras.utils import normalize from keras.utils import to_categorical import matplotlib.pyplot as plt
Step 2: Load the MNIST dataset
Since the MNIST dataset is hugely popular, it can easily be easily accessed from different sources. Even TensorFlow and Keras allow us to download it through their respective API directly. Thus, we will download it through Keras’ API.
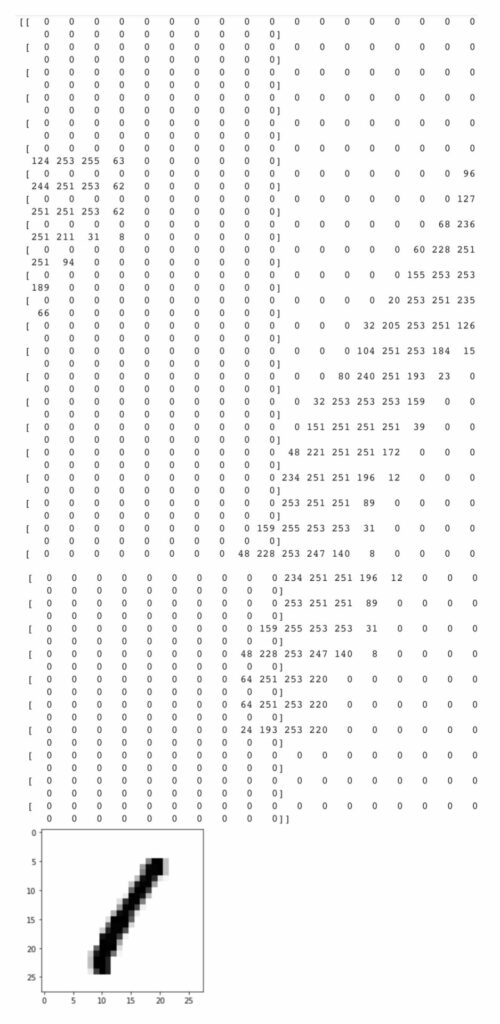
mnist_dataset = tensorflow.keras.datasets.mnist # Split the data into training and test sets. (train_X, train_Y), (test_X, test_Y) = mnist_dataset.load_data() # train_X represents the pixel values (feautures) of the 28 x 28 image. print(train_X[3]) plt.imshow(train_X[3],cmap=plt.cm.binary) plt.show()
Output:
Step 3: Build the Model
We have decided to go for a 4-layered model i.e., having two hidden layers and an input and output layer. The rectifier activation function is chosen for the neurons in the hidden layers.
# 4-layered model model = models.Sequential() # Hidden layer containing 512 units. Rectifier linear function is used as the activation function. model.add(layers.Dense(512, activation='relu', input_shape=(28 * 28, ))) model.add(layers.Dense(128, activation=tensorflow.nn.relu)) # Dropout is a regularization technique that is used to reduce overfitting. model.add(layers.Dropout(0.2)) # Output layer which is 10-way softmax layer, which returns an array of 10 probability scores displaying the probabability of image of the digit belonging to which of the 10 classes. model.add(layers.Dense(10, activation='softmax'))
Step 4: Normalize the data i.e., change the current data range from 0 to 255 to 0 and 1 inclusive.
It is considered a good practice to scale input values when it comes to neural networks. Thus we will normalize our data.
train_X = normalize(train_X, axis=1)
test_X = normalize(test_X, axis=1)
print(train_X[3])
print(" ")
print('Shape of train_X: ', train_X.shape)
print('Number of images in train_x: ', train_X.shape[0])
print('Number of images in test_X: ', test_X.shape[0])
Output:

Step 5: Flatten each 28 x 28 image to 1 x 784 image
The training dataset is structured to be a 3-dimensional array. To be able to use the dataset in Keras API, we need 4-dimensional NumPy arrays. Therefore, we need to flatten or reduce the images so that they represent a vector of pixels. In this case, since the image is 28 x 28, there will be 784-pixel values.
train_X = train_X.reshape(train_X.shape[0], -1)
test_X= test_X.reshape(test_X.shape[0], -1)
# Encode labels
train_Y = to_categorical(train_Y)
test_Y = to_categorical(test_Y)
print('Shape of train_X: ', train_X.shape)
print('Number of images in train_x: ', train_X.shape[0])
print('Number of images in test_X: ', test_X.shape[0])
Output:

Step 6: Train the model
We will now fit the model.
model.fit(train_X, train_Y, epochs=7)
Output:

Step 7: Evaluate the model accuracy on test data
We will now evaluate the accuracy of the model.
_, test_accuracy = model.evaluate(test_X, test_Y, verbose=0)
print(f"\nTest Accuracy : {test_accuracy * 100} %")
Output:
97.85% seems quite great? Isn’t it? No, never satisfy! In the next section, we will discuss how to improve it even more!



