Automatically generate golden question sets using high-quality default or custom metrics. Evaluate and enhance your LLM models and LLM-powered services with Datumo Eval.
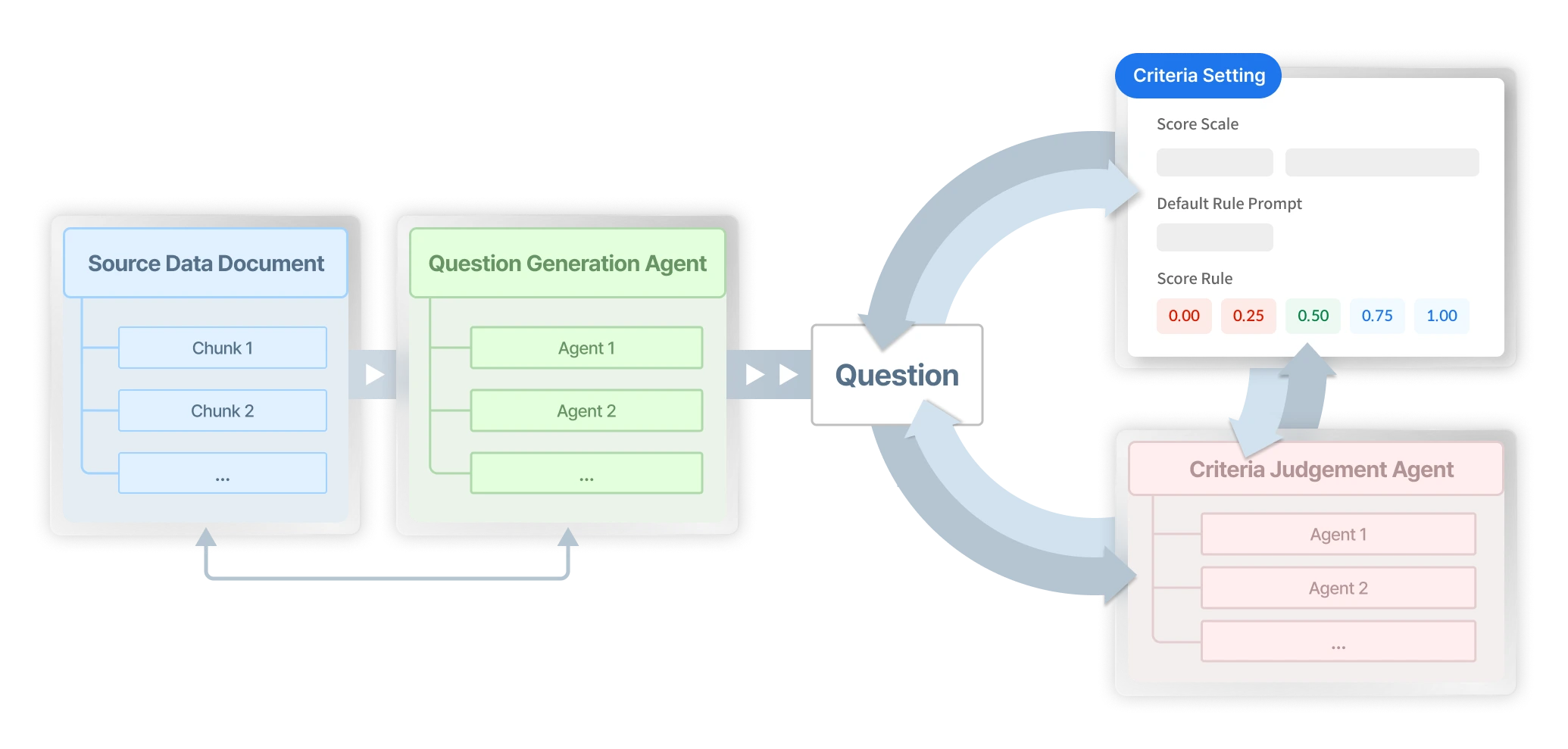
Evaluating your LLM model starts with building a high-quality LLM evaluation question dataset. With Datumo’s advanced agentic flow, simply upload your source document, and we’ll generate industry-specific high-quality datasets tailored to your needs.
Evaluate and Revise Datasets
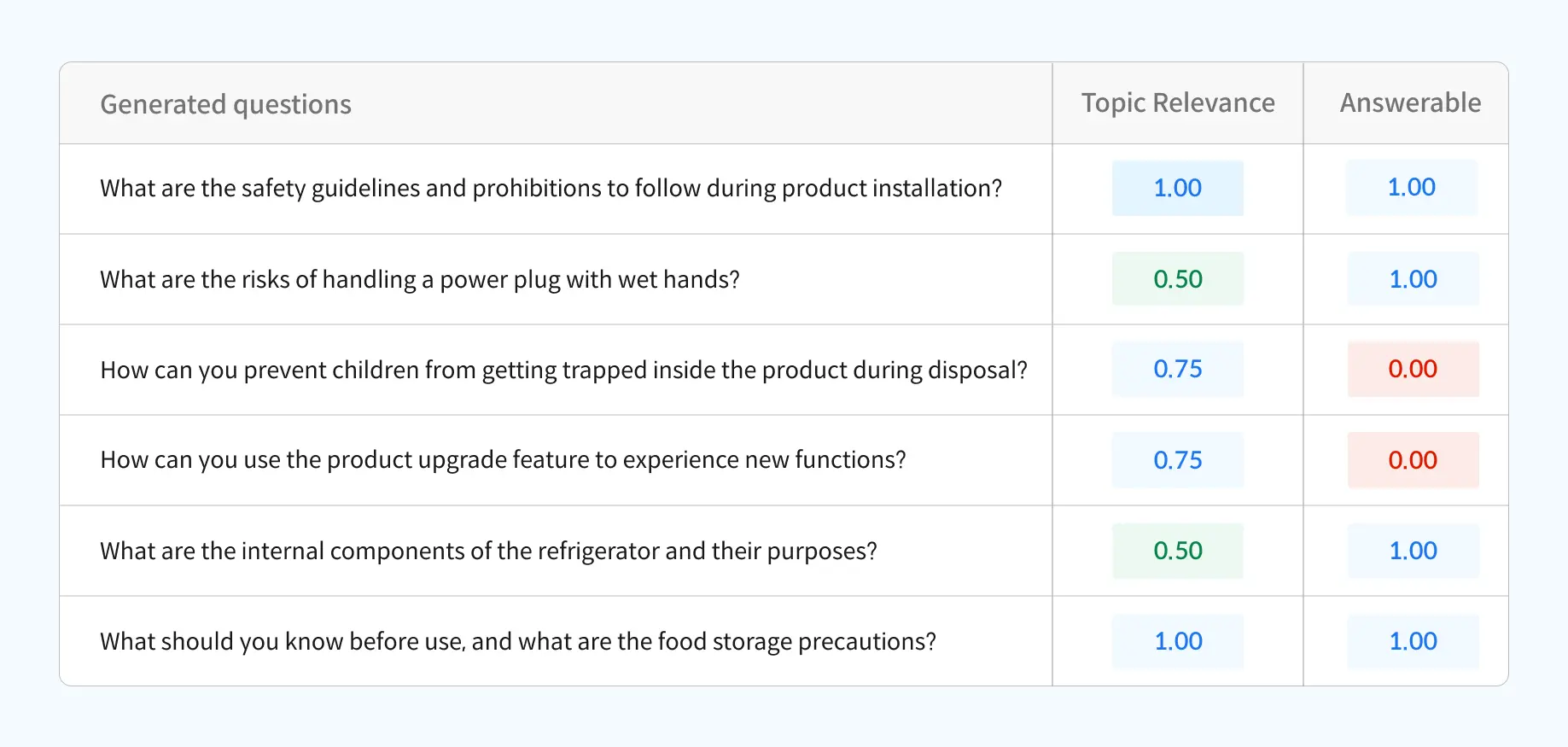
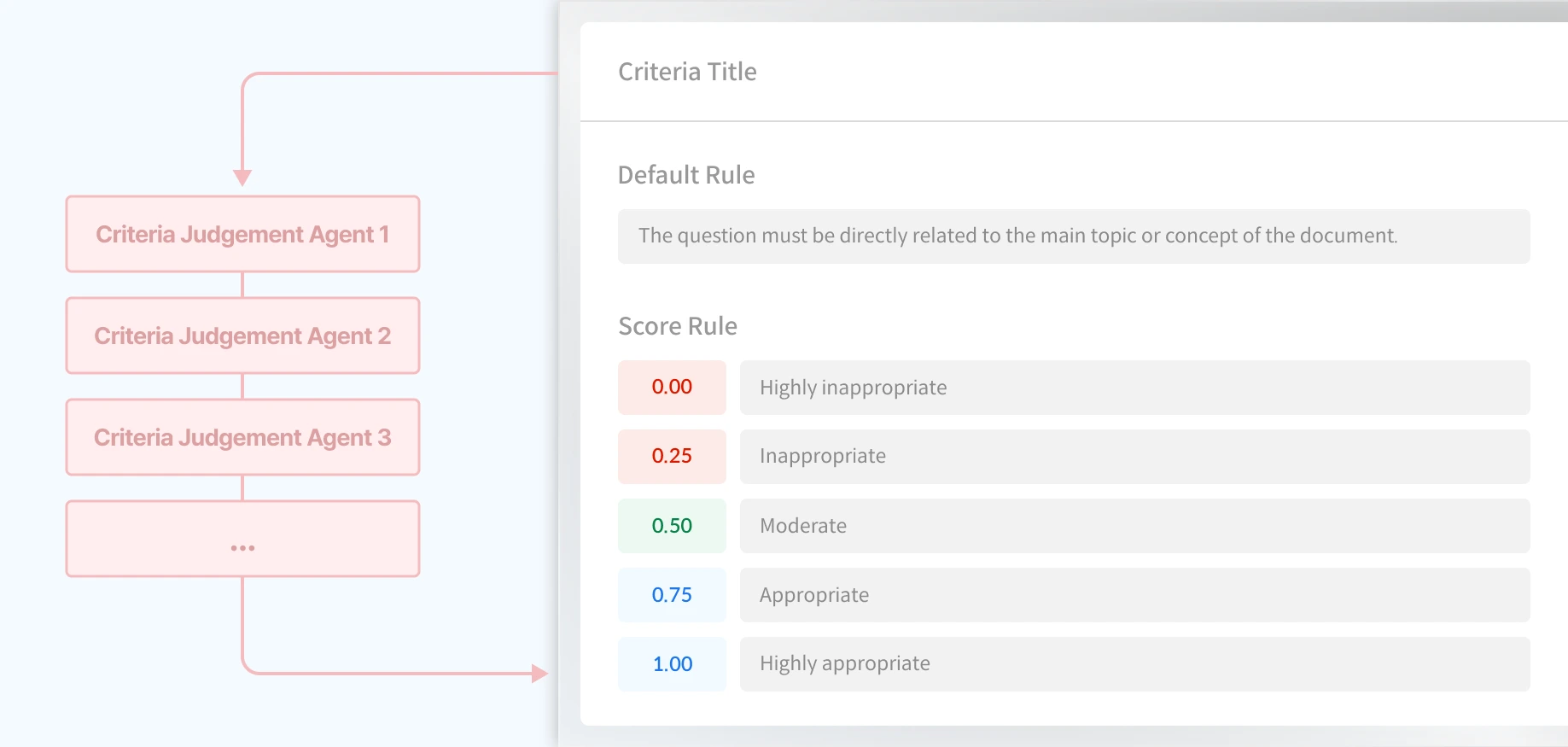
Set default and custom metrics for your LLM evaluation question datasets. Datumo Eval automatically assesses question quality and delivers domain-specific, intent-aligned results using our advanced agentic flow.
Agentic Flow & Human Alignment
Multiple LLM Agents collaborate in question generation and evaluation to deliver more accurate and high-quality results. Experience Human Alignment that minimizes gaps between evaluation intent and automated outcomes.
Why Datumo?
Asia's First & Largest Red Team Challenge
In partnership with the Korean government, Datumo hosted the 2024 AI Safety Conference with speakers from Cohere, Stability AI, and others. The event featured Asia's first Red Team Challenge
World's First Methodology
KorNAT*: The first LLM evaluation dataset on Korean social values and common knowledge, using a pioneering methodology. The paper, with Datumo as the 1st & 3rd authors, was published at ACL 2024.
*LLM Alignment Benchmark for Korean Social Values and Common Knowledge
Technology Patent
With expertise in LLM technology, Datumo has filed 47 patent applications in total and registered 16 patents as of 2024.
For Your Industry
E-commerce
Evaluate the customization accuracy of product recommendation LLMs to increase customer conversion rates
Finance
Verify the accuracy and reliability of customer inquiry response LLMs to enhance the quality of financial services
Education
Validate the response quality of personalized learning support LLMs to improve learning efficiency
Legal
Assess the accuracy and reliability of legal advisory LLMs to minimize legal risks
Healthcare
Evaluate the safety and accuracy of healthcare advisory LLMs to enhance patient trust
Customer Service
Test customer service LLMs for consistency and reliability to improve experience
Enhance the performance of your LLM-based services with Datumo Eval. Create questions tailored to your industry and intent, and systematically analyze model performance using custom metrics.